한국어판 안내: 이 문서는 capx-paper-2026-04.tex의 제출용 영어 논문을 한국어로 읽기 쉽게 옮긴 companion 문서입니다. arXiv 제출본은 영어 LaTeX/PDF이며, 본 문서는 별도 참고용입니다. 참고문헌은 공개 논문/벤치마크만 포함하고, 프로젝트 내부 노트나 자동 생성 문서는 논문 참고문헌으로 쓰지 않습니다.
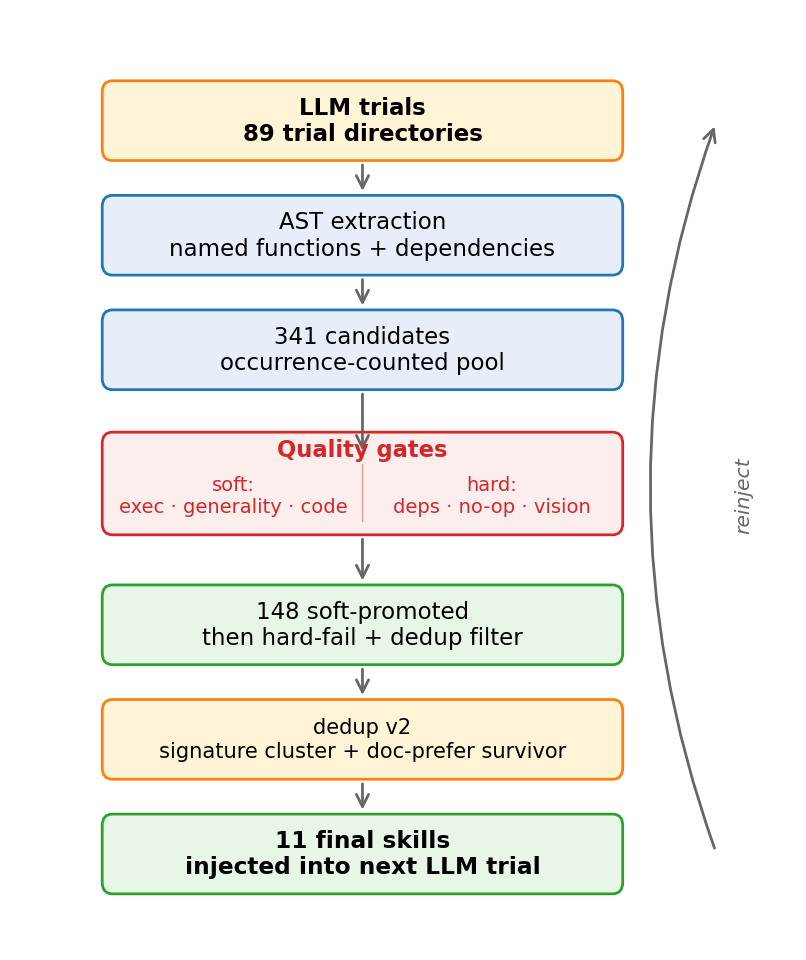
본 연구는 NVIDIA CaP-X에서 출발해, LLM 로봇 코드 생성 에이전트가 과거에 생성한 Python 함수들을 실행 가능한 스킬 라이브러리로 채굴하고 이후 trial에 다시 주입받을 때 성능 이득을 얻는지 검정한다. capx는 Code-as-Policies 스타일의 cube_lifting 파이프라인에 skill memory layer를 추가한다. 생성된 함수는 AST로 추출되고, quality gate와 선택적 dedup을 거친 뒤, 다음 trial의 prompt와 execution namespace에 다시 들어간다. 북극성 가설은 단순하다. “채굴된 실행 가능한 함수 body가 실제 로봇 코드 생성을 개선해야 한다.”
v1의 가장 강한 결과는 조건부 긍정이다. gpt-4.1에서 no-skill baseline(P21_a)은 39/50 = 78.0%에 수렴했다. no-dedup mined-skill library인 namespace-enabled 16-skill arm(C1)과 gated 14-skill arm(C2)은 각각 67/70 = 95.7%, 68/70 = 97.1%를 기록했고, Wilson 95% CI도 baseline과 분리되었다. typed empty-stub control(empty_ns)은 13/30 = 43.3%에 그쳐, 단순히 타입이 있는 namespace가 아니라 실행 가능한 function body가 성능에 기여함을 보였다.
그러나 production-style dedup은 이 이득을 보존하지 못했다. production structural-dedup library(C3v2)는 58/70 = 82.9%로 baseline과 통계적으로 구분되지 않았고 C2보다 14pp 낮았다. 반면 gated no-dedup library(C2)에서 quality score가 낮은 세 스킬만 제거한 quality-ranked same-size library(manual_11)는 66/70 = 94.3%를 기록했다. 이는 손상이 “스킬 수 제한”이 아니라 survivor selection 문제임을 시사한다.
따라서 v1의 결론은 좁다. cube_lifting에서는 no-dedup mined-skill library가 no-skill baseline을 이긴다. 하지만 현재 structural dedup은 이 이득을 지울 수 있다. cube_stack과 LIBERO는 floor effect로 인해 transfer를 아직 측정하지 못했고, Claude/DeepSeek의 no-dedup gated library(C2) endpoint는 높지만 해당 backbone의 no-skills baseline을 재측정하지 않았으므로 cross-backbone baseline delta는 주장하지 않는다.
CaP-X 계열 파이프라인은 LLM에게 작은 base API 집합을 보여주고, LLM이 로봇을 제어하는 Python 코드를 작성하게 한다. 생성 코드는 시뮬레이터에서 실행되고, Visual Differencing Model(VDM)이 성공 여부를 판단해 실패 시 재생성을 요구한다. 이 구조는 LLM의 code-generation loop를 관찰하기에 좋다. 어떤 함수가 생성되었는지, 어떤 error trace가 발생했는지, 어떤 retry가 일어났는지가 모두 artifact로 남는다.
본 연구는 여기에 하나의 가설을 더한다. LLM이 만든 함수들 중 일부가 재사용 가능한 robot-control subroutine이라면, 그 함수들을 이후 trial에 다시 주입했을 때 no-skills baseline보다 좋아져야 한다. v1의 claim ladder는 다음과 같다.
cube_lifting에서 no-dedup mined-skill library는 no-skill baseline(P21_a)보다 높다.파이프라인은 다음 순서로 동작한다.
Quality gate는 execution success rate, source-task generality, code quality를 soft signal로 사용하고, dependency resolution, non-noop body, vision-server availability를 hard-fail signal로 사용한다.
Namespace seeding은 execution 단계의 핵심 수정이다. skill code를 exec()로 올릴 때 base API callable, sibling skill, pure-numpy utility를 같이 넣어야 한다. 그렇지 않으면 promoted skill이 solve_ik(...) 같은 base API를 호출할 때 NameError가 발생한다.
Dedup은 구조적으로 비슷한 함수를 같은 cluster로 묶고 survivor를 하나 선택한다. v1에서 중요한 발견은 이 survivor rule이 매우 민감하다는 점이다. structural-hash dedup은 LLM이 실제로 호출하기 어려운 no-docstring variant를 survivor로 고르는 경우가 있었고, 이 선택이 성능을 떨어뜨렸다.
Group D 50개 trial과 89개 retry directory, 227개 code block을 재분석했다. promoted skill 11개 중 상위 4개가 전체 call의 76%를 차지했고, 두 스킬은 완전히 dead skill이었다.
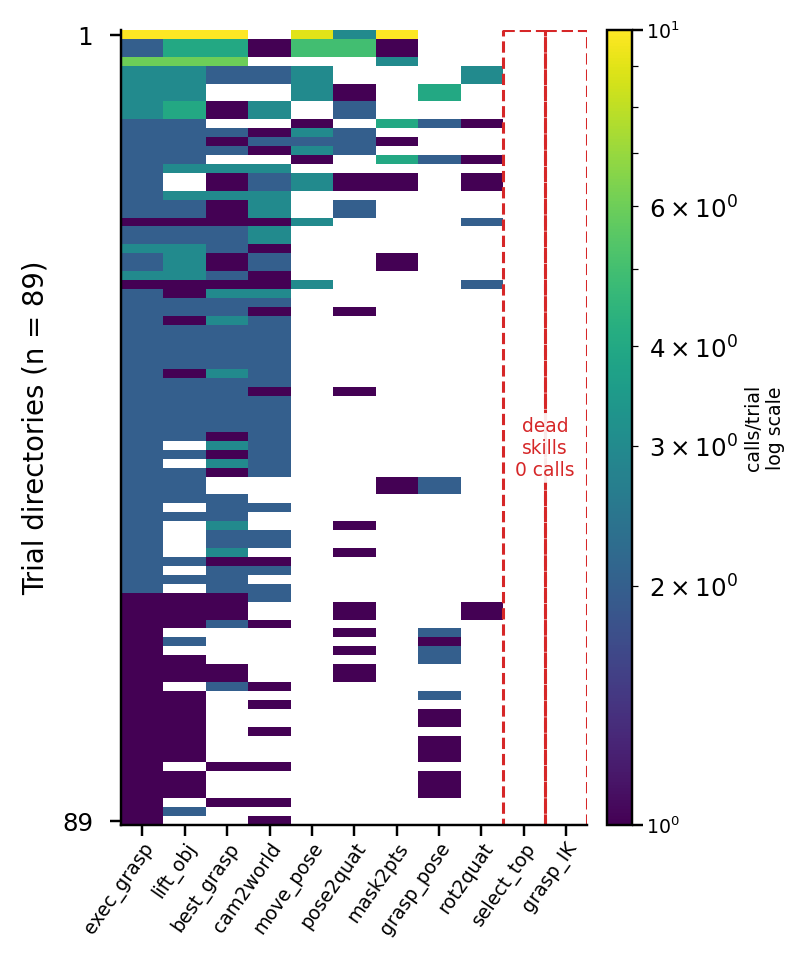
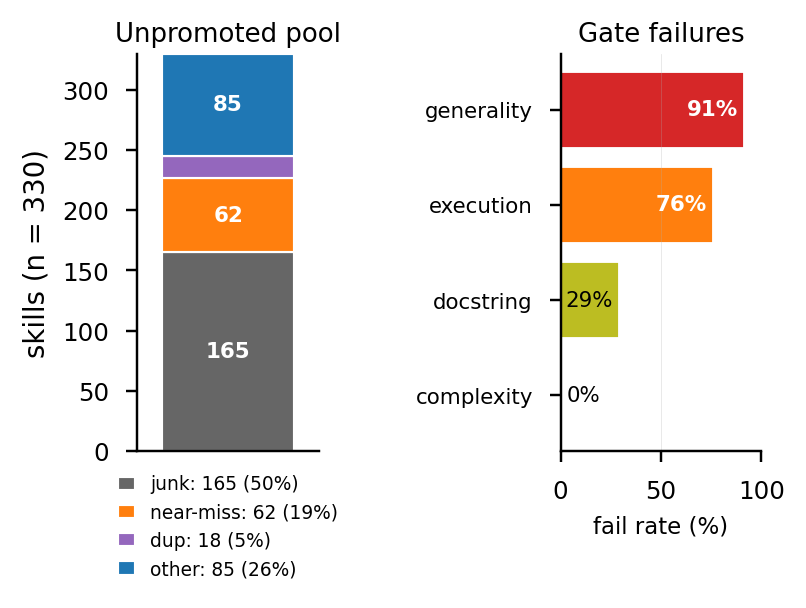
unpromoted pool은 330개 후보로 컸지만, 대부분은 occurrence=1이거나 success gate를 통과하지 못했다. 동시에 promoted skill과 structural hash가 같은 unpromoted duplicate도 18개 있었다. 즉 문제는 단순히 “좋은 함수를 못 찾는다”가 아니라 naming explosion과 survivor selection이었다.
retry 분석에서는 LLM이 실패 후 고수준 skill set을 그대로 반복하기보다 skill set을 바꾸거나 primitive로 내려가는 경향을 보였다. 이는 abstraction downgrade 전략으로 해석된다.
cube_lifting을 개선하는가| 실험 arm | 내부 ID | 구성 | 결과 | 해석 |
|---|---|---|---|---|
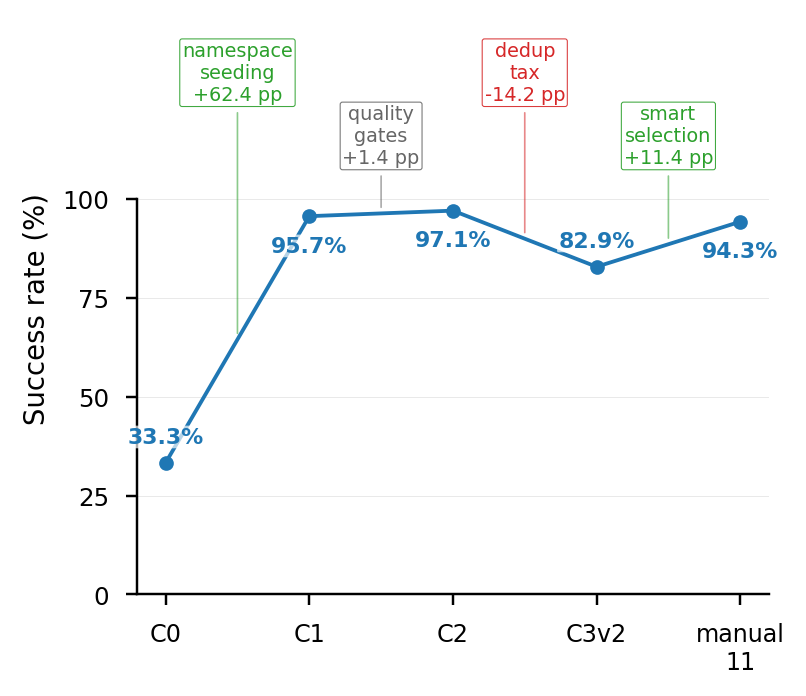
| Broken-namespace diagnostic | C0 | 기존 16 skills, namespace seeding off | 5/15 = 33.3% | namespace bug 재현 |
| Namespace-enabled no-dedup library | C1 | 기존 16 skills, namespace seeding on | 67/70 = 95.7% | namespace seeding 효과이자 powered no-dedup arm |
| No-dedup gated mined-skill library | C2 | gates 적용, no dedup | 68/70 = 97.1% | v1 최강 조건 |
| Production structural-dedup library | C3v2 | dedup v2 + 11 skills | 58/70 = 82.9% | survivor-selection tax |
| No-skill baseline | P21_a | no skills | 39/50 = 78.0% | powered baseline |
| Quality-ranked same-size library | manual_11 | C2에서 quality 하위 3개 제거 | 66/70 = 94.3% | smarter selection 가능 |
| Typed empty-stub control | empty_ns | typed empty skill stubs | 13/30 = 43.3% | function body가 중요 |
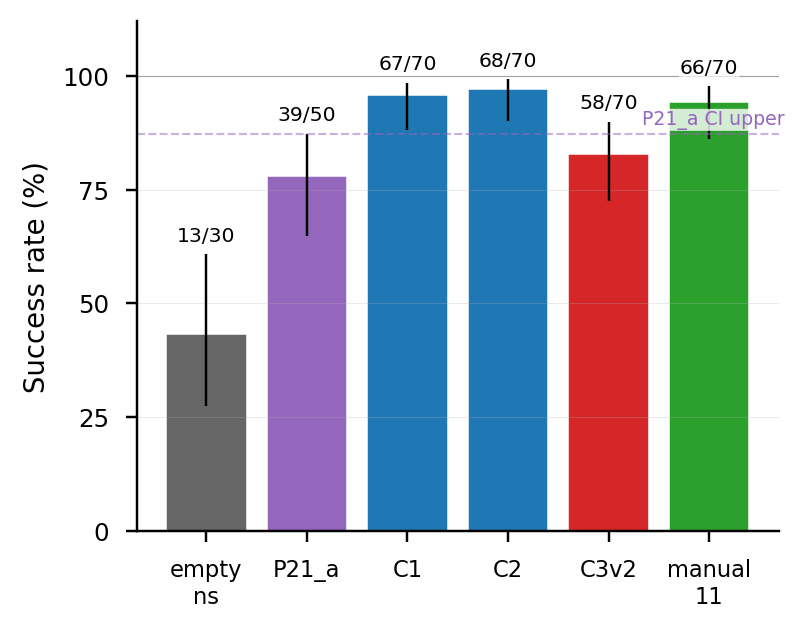
핵심 비교는 no-skill baseline(P21_a)와 no-dedup gated mined-skill library(C2)다. C2의 Wilson CI는 P21_a와 분리되므로, no-dedup library는 cube_lifting에서 baseline을 이긴다. typed empty-stub control(empty_ns)이 낮은 것은 이 이득이 namespace surface가 아니라 실행 가능한 body에서 온다는 근거다.
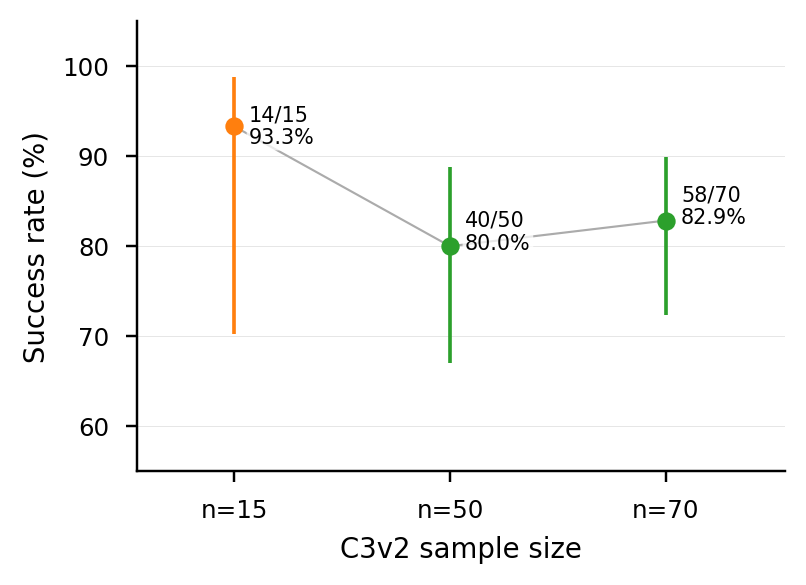
production structural-dedup library(C3v2)는 초기 n=15에서 14/15 = 93.3%로 좋아 보였지만, n=50, n=70으로 늘리자 80.0%, 82.9% 근처로 안정화되었다. 반면 같은 11개 스킬 수의 quality-ranked same-size library(manual_11)는 66/70 = 94.3%에 도달했다. 따라서 손상은 library size 자체가 아니라 어떤 variant를 survivor로 남기느냐의 문제다.
Docstring forced-choice 실험도 같은 방향을 가리킨다. task-fit이 같은 두 variant 중 하나에만 docstring을 넣으면 LLM은 docstring-bearing variant를 압도적으로 선호했다. 즉 dedup은 단순 structural hash가 아니라 LLM이 실제로 인지하고 호출할 수 있는 survivor를 남겨야 한다.
cube_stack과 LIBEROcube_stack에서는 baseline과 skill-injected condition 대부분이 floor에 가까웠다. 실패 원인은 skill layer보다 base pipeline 쪽에 가까웠다. deprecated SciPy API 호출, SAM3 JSON serialization 문제, “green cube not found”, 1000초 timeout 등이 포함된다. C3v2가 2/12 성공한 것은 stack 자체가 불가능한 것은 아님을 보여주지만, 이 regime에서는 skill-library effect를 측정하기 어렵다.
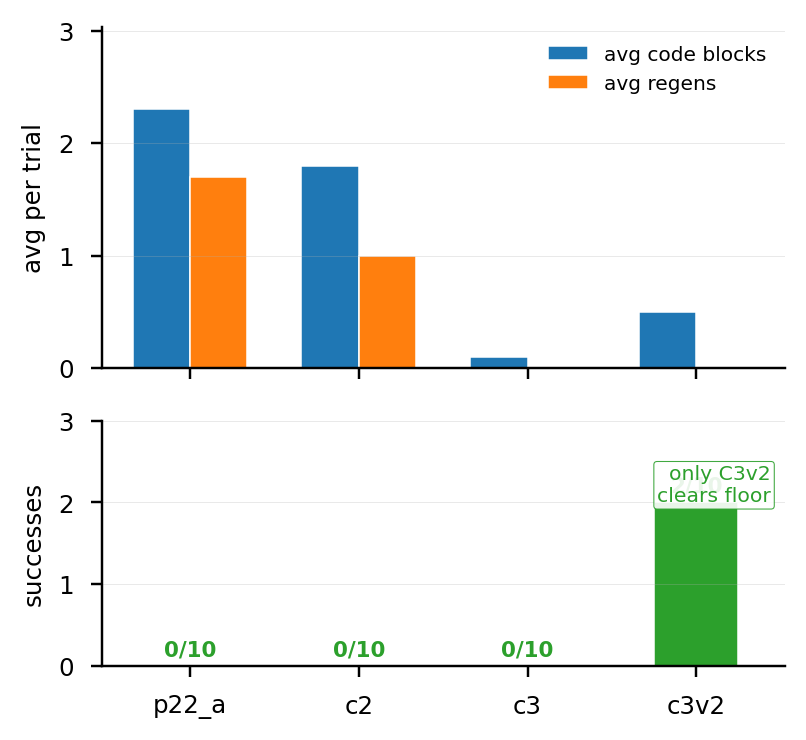
LIBERO도 비슷했다. Spatial 0 smoke는 0/5였고, 더 단순한 Spatial 2와 Object 0도 각각 0/5였다. privileged perception을 사용해 perception을 우회한 조건도 1/10에 그쳤다. 따라서 LIBERO floor는 perception-only 문제가 아니며, control API, prompt format, simulator semantics까지 포함한 environment work가 필요하다.
v1에서 강하게 주장할 수 있는 것은 다음이다.
cube_lifting에서 no-dedup mined-skill library는 no-skill baseline보다 성능이 높다.반대로 다음은 아직 주장하면 안 된다.
cube_lifting 밖으로 일반화된다고 말하면 안 된다.cube_lifting에서 채굴되었다.cube_stack과 LIBERO는 floor에 가까워 skill effect를 측정할 수 없었다.C2) endpoint만 확인했고 baseline은 재측정하지 않았다.NVIDIA CaP-X에서 출발해 실행 가능한 mined skill memory를 추가했을 때, cube_lifting에서는 no-dedup library가 no-skills baseline을 명확히 이겼다. no-dedup gated library(C2)는 68/70 = 97.1%, no-skill baseline(P21_a)은 39/50 = 78.0%였고, typed empty-stub control(empty_ns)은 13/30 = 43.3%였다. 따라서 실제 function body가 성능 이득을 만든다는 근거가 있다.
동시에 v1은 일반화 논문이 아니다. structural dedup은 이 이득을 지울 수 있고, cube_stack과 LIBERO는 floor라 transfer를 측정하지 못했다. 북극성 가설은 좁은 형태로 살아 있다. 자동 채굴된 실행 스킬은 도움이 될 수 있지만, 다음 논문급 질문은 cube_lifting 밖의 중간 난이도 task에서 Dedup v3가 같은 효과를 보존하는지 검정하는 것이다.