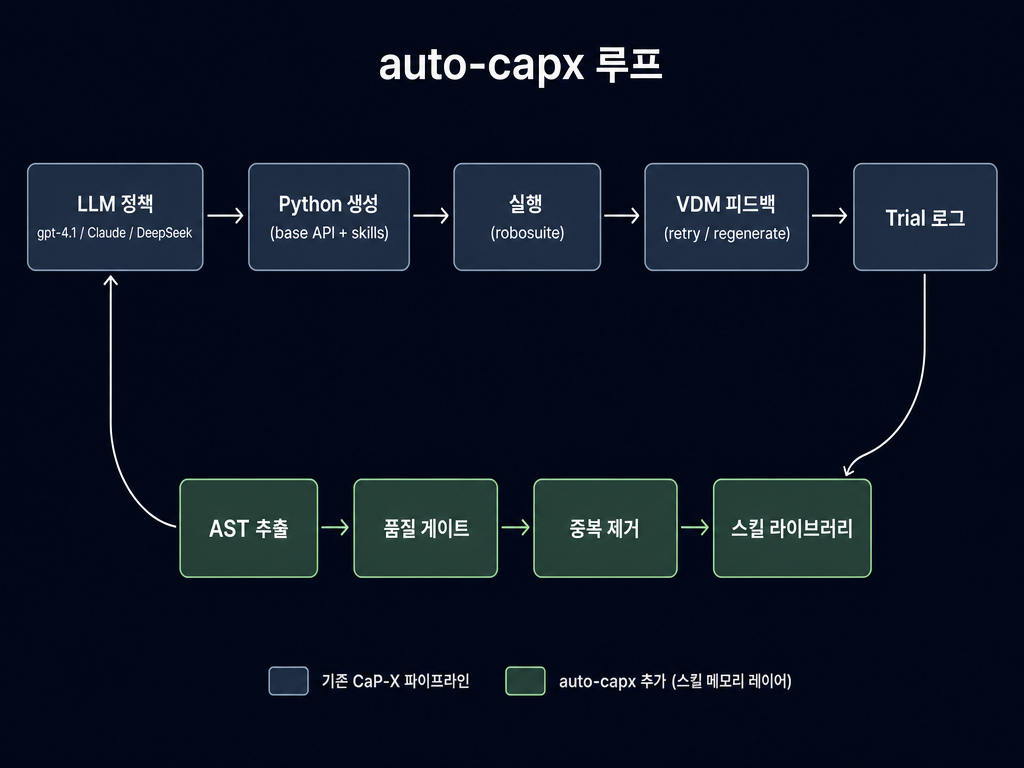
4무엇을 발견했는가
발견 1 — Library 가 도움이 됨 조건부 Yes
"큐브 1 개 들기" task 에서 도구 상자 적용 시 78% → 97% (gpt-4.1 기준). 19pp 개선이며 통계적으로 단단합니다.
단 *어떤 알고리즘으로 도구 상자를 정리하는가* 가 결정적입니다. 동일한 11 개 도구라도 잘못 고르면 78% → 83% (효과 미미), 잘 고르면 78% → 94%.
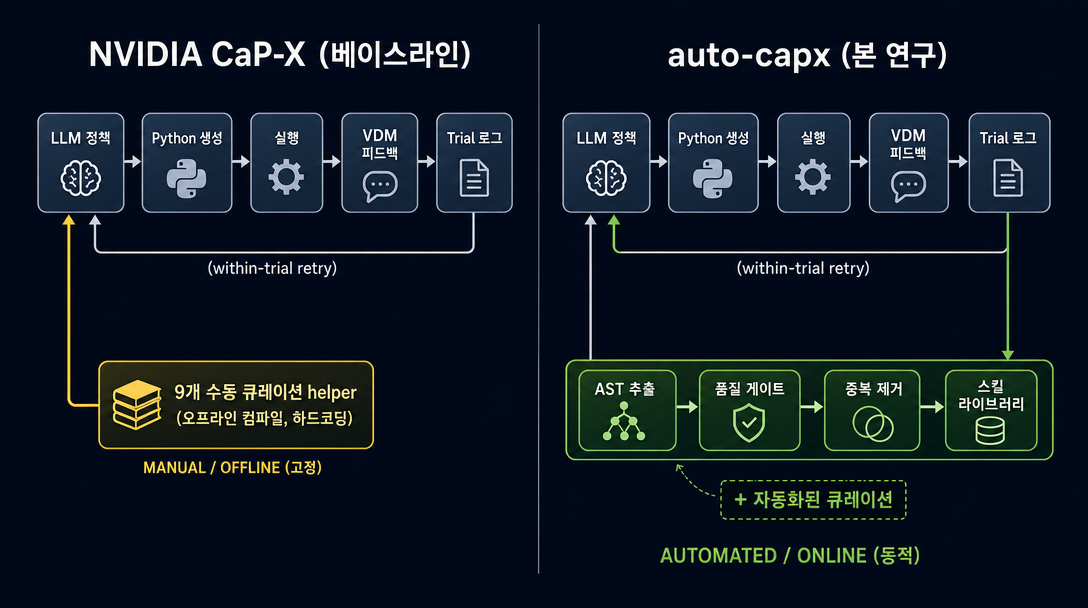
NVIDIA 의 수동 도구 상자와의 비교: NVIDIA 도 사람이 직접 만든 9 개짜리 도구 상자를 제공합니다 — 수백 번의 trial 에서 사람이 골라낸 최선의 9 개입니다. auto-capx 의 자동 도구 상자도 거의 같은 수준의 성능을 보입니다. gpt-4.1 기준: NVIDIA 수동 9 개 → 90%, 자동 14 개 → 97%. DeepSeek 기준: NVIDIA 수동 9 개 → 84%, 자동 11 개 → 94%. 단 정확히 표현하면 "이 단일 task n=50 setting 에서 자동 큐레이션이 NVIDIA 수동 큐레이션과 통계적으로 구분되지 않는다" 입니다 (Wilson 95% CI overlap, 방향성은 자동 쪽 +7~10pp). 사전등록된 equivalence margin 없이 측정한 결과라서 "수동 큐레이션을 대체했다" 보다는 "단일 task 에서 비슷한 수준에 도달했다" 가 정확한 표현입니다.
발견 2 — 모든 LLM 에서 같은 효과를 보이는가 Yes, 단 magnitude 가 다름
| 모델 | 도구 상자 없음 | NVIDIA 수동 9 개 | 자동 도구 상자 |
|---|
| gpt-4.1 | 78% | 90% | 97% |
| Claude Sonnet 4 | 86% | — (미실행) | 98% |
| DeepSeek v3 | 6% | 84% | 94% |
가장 약한 모델이 가장 큰 이득 을 봅니다. DeepSeek 은 도구 상자가 없으면 거의 작동하지 않지만 (6%), 도구 상자가 주어지면 94% 까지 도달합니다.
DeepSeek 만 차이가 큰 이유는 무엇인가: 자세히 살펴보면 DeepSeek 도 "잡았다가 떨어뜨리는" 수준까지는 도달합니다 (reward 0.5–0.7). 단 실패 후 재시도 단계에서 DeepSeek 는 비슷한 실수를 반복합니다. Claude 는 1–2 번 만에 수정합니다. 즉 library 가 망가진 자기 수정 (self-correction) 을 대체 하는 것이 핵심 메커니즘이며, 추론력의 차이가 아닙니다. 그리고 이 효과는 auto-capx 의 자동 도구 상자에만 특별한 것이 아닙니다 — NVIDIA 의 수동 도구 상자도 동일하게 DeepSeek 을 6% → 84% 로 끌어올립니다. 즉 어떤 좋은 도구 상자라도 DeepSeek 의 약한 베이스라인을 끌어올린다는 의미입니다.
발견 3 — 다른 task 에서도 통하는가 Floor (벽에 부딪힘)
"큐브 3 개 차곡차곡 쌓기" task 를 추가하여 측정한 결과 0/15 (베이스라인과 library 모두 0%). 도구 상자가 있어도 task 자체가 풀리지 않습니다.
원인은 vision pipeline 입니다. 큐브가 3 개 있어 카메라가 개별 객체를 잘 구분하지 못합니다 (mask 가 200 개 이상 조각으로 쪼개짐). LLM 이 아무리 우수해도 카메라 출력이 엉망이면 해결할 방법이 없습니다.
비유: 요리사 비유로 돌아가면 — 식재료를 받았으나 재료가 부서져 식별 자체가 불가능한 상태입니다. 레시피가 아무리 좋아도 요리할 수 없습니다.
흥미로운 부수 발견 한 가지: 도구 상자가 있을 때 코드 작성 자체가 27% 더 빠릅니다 (성공/실패 무관). "library 가 도움이 된다" 가 *task 성공률* 과 *코드 효율성* 두 갈래로 나뉘어 나타납니다.
발견 4 — 두 번째 시즌 도구 추가가 가능한가 No, 포화 상태
한 번 도구 상자를 구성한 뒤, 그 도구 상자를 사용하여 다시 trial 을 돌리면서 "새 도구가 추가로 나오는가" 를 측정하였습니다. 결과: 0 개 추가.
이유는 다음과 같습니다. LLM 이 *충분히 좋은 도구 상자* 를 받으면 새 함수를 만들 동기가 사라집니다. 기존 함수의 조합으로 모든 task 를 해결합니다. 새로 발명할 도구가 더 이상 남아 있지 않은 상태입니다.
비유: 요리사에게 칼, 도마, 냄비, 프라이팬, 거품기, 체, 거름망까지 모두 제공한 상태입니다. 더 이상 새로 발명할 도구가 없습니다. 모든 요리는 *조합* 으로 해결됩니다.
발견 5 — 어떤 함수가 살아남는가 네 가지 패턴
- 설명 (docstring) 이 있는 함수 — LLM 이 8 배 더 자주 호출합니다. 두 변종 중 골라야 하는 상황에서 100% 설명이 있는 쪽을 선택합니다.
- 파이프라인 허브 위치의 함수 —
execute_grasp 같은 핵심 함수는 모든 trial 에서 호출됩니다. 변두리 함수는 retry 시에만 등장합니다.
- retry 시 부서지는 패턴 — high-level skill 실패 시 LLM 이 그 내부의 low-level 함수로 풀어 헤칩니다 (인간의 디버깅과 유사).
- 약한 모델의 자기 수정 대체 — 발견 2 의 mechanism. Library 가 망가진 iteration loop 를 대체합니다.