C2 success — no-dedup library
The "ship this" arm: namespace seeding + gates + no structural dedup.
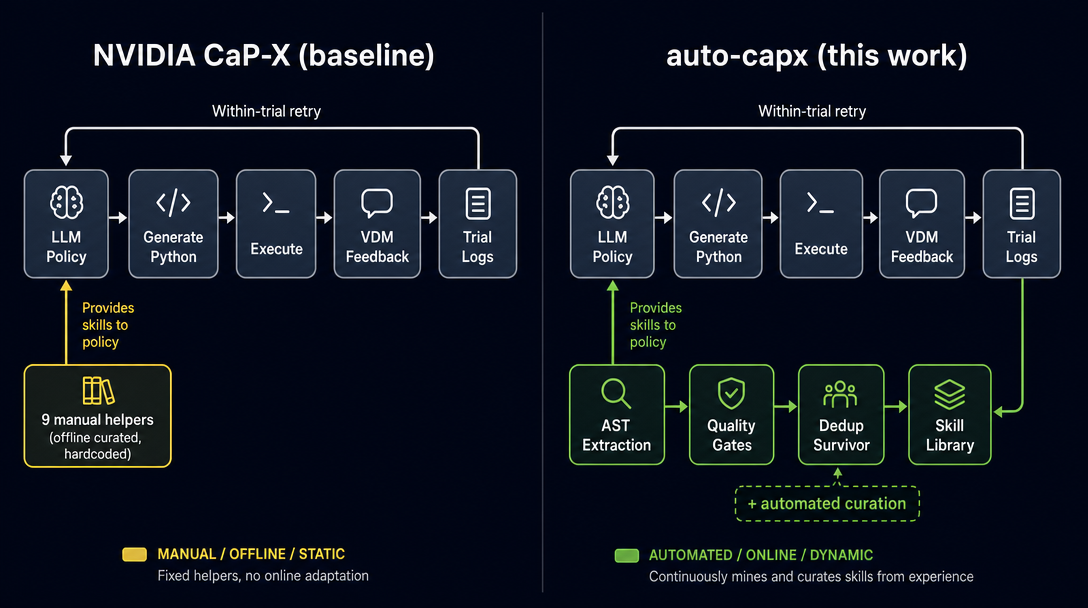
Agentic coding pipelines share a recurring loop — discover useful subroutines from prior generations, accumulate them into a library, re-apply them later. NVIDIA CaP-X already ships with a skill library, but those helpers were manually curated by researchers reading many LLM trial programs. auto-capx (this work) instantiates that self-improvement loop on CaP-X and tests whether an automatic mining loop can match — or, under some conditions, improve on — NVIDIA's hand-curation step on a single concrete task. The broader direction this points at: code-as-policy robots that scale to wider settings without humans hand-expanding their helper API. Single-task, reduced-API evidence so far; the cross-setting claim is not yet tested. Four research questions on the way: extract → useful → evolve → survive.
Status: paper v12 · NVIDIA-9 closure integrated · arXiv submission tar 151 KB · cumulative cost ~$261.
NVIDIA CaP-X gives an LLM a small base API plus a manually-curated set of helper skills (9 functions in the published S3 configuration, FrankaControlApiReducedSkillLibrary). The helpers were chosen offline by NVIDIA's authors from ~182 unique functions across hundreds of trials, filtered to ~73 candidates, then human-selected to 9. auto-capx (this work) instantiates an agentic self-improvement loop on top of CaP-X — mine subroutines from prior generations → gate → dedup → re-inject into later trials — and tests whether that automatic loop can reach performance comparable to NVIDIA's hand-curation step in this reduced-API setting: trial Python is parsed, gated, optionally deduplicated, and re-injected into later prompts and execution namespaces — no human in the loop. The broader direction: a code-as-policy robot agent that scales to wider settings without humans hand-expanding the helper API. The diagrams below show the curation difference; the experiments compare auto-mined library variants against nvidia9 (NVIDIA's published 9-skill library, the proper baseline) and against P21_a (a no-helpers ablation used as the anchor point for "+pp" gains).
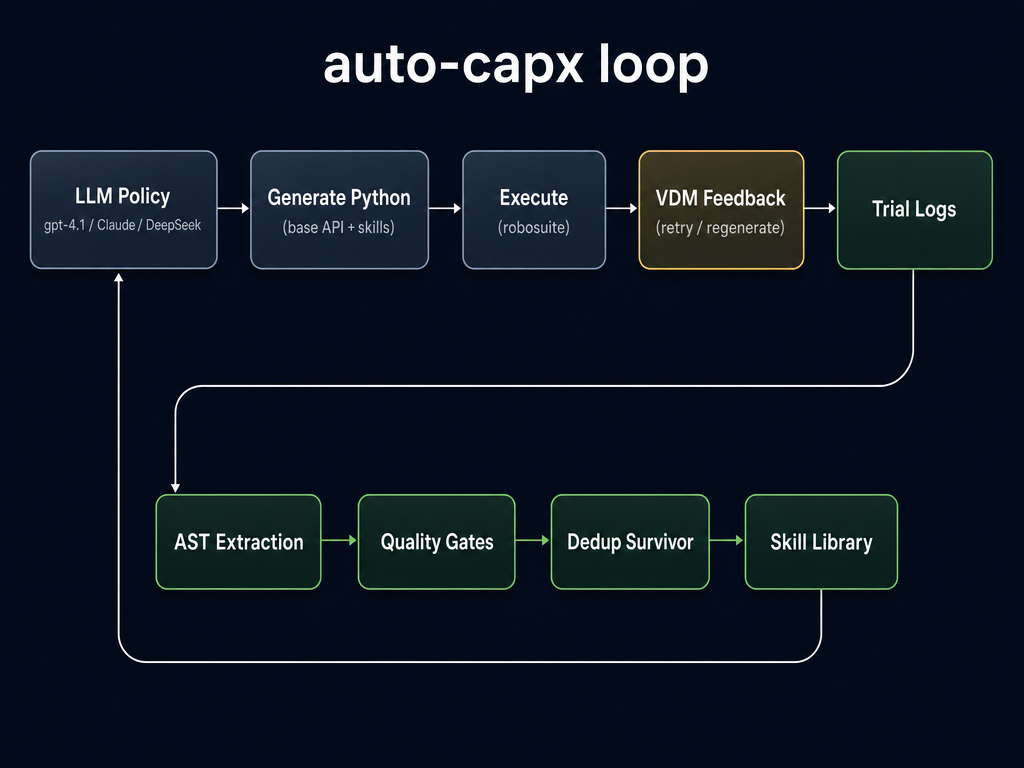
Both setups share the within-trial loop (LLM → Python → execute → VDM → retry). auto-capx adds the bottom row: extract reusable functions from trial logs, gate them, dedup, and re-inject the resulting library into the LLM's namespace on subsequent trials. Everything in this paper is the ablation of that bottom row.
Each card explains what is in the library, what gets tested by it, and why it matters. The library size is the most important number on each card — the dedup story (Q2d) hinges on whether two libraries with the same size behave differently.
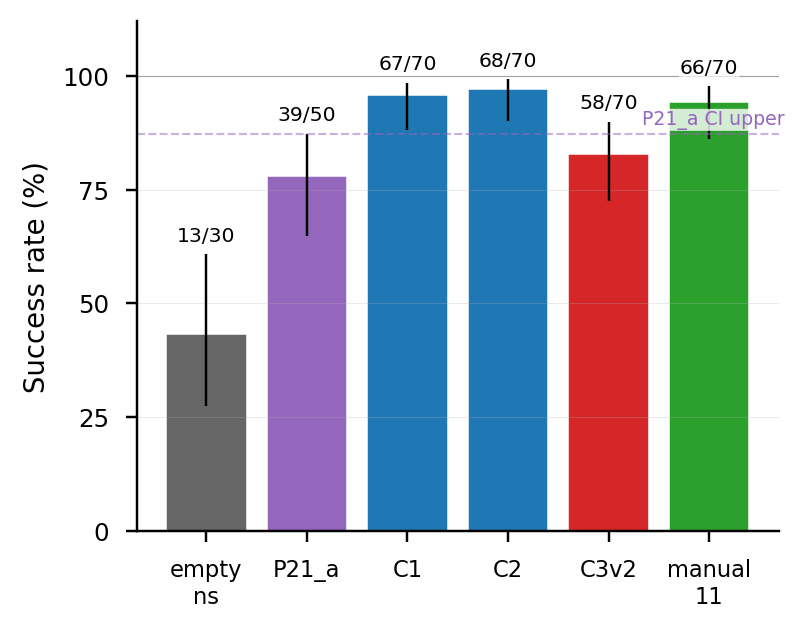
The reference point. The robot code agent gets only the base CaP-X-style API — no mined skills at all. Everything else (P21_a's success rate at $n{=}50$ is 78.0%) is what we compare against.
Everything quality gates passed, no dedup. All 16 mined functions injected into prompt + execution namespace. Namespace seeding (the runtime fix that makes promoted skills find their dependencies) is active.
Quality-gated 14 skills, no dedup. C1 with the two lowest-passing skills removed. This is the arm the paper recommends shipping ("namespace seeding + gates + no structural dedup").
C2 + structural-hash dedup. The current production survivor rule clusters functions by AST hash and keeps one per cluster. Library size shrinks to 11. The downstream effect is the central counter-evidence: this arm is statistically indistinguishable from the no-skill baseline.
Same 11 skills size, picked by quality_score instead of structure. Take C2's 14 skills, sort by quality_score desc, keep the top 11 (drops the 3 weakest). Same library size as C3v2 but different survivors.
16 function signatures with empty bodies (pass). The LLM sees the typed namespace exactly like in C1, but the executable bodies are gone. Used to ask: is a typed scaffolding alone enough?
NVIDIA's manually-curated 9-skill library, hardcoded as class methods on FrankaControlApiReducedSkillLibrary. The 9 helpers were selected by NVIDIA's authors by offline compilation: ~182 unique functions across hundreds of LLM trials, filtered to ~73 candidates, then human-picked to 9. This is NVIDIA's published S3 configuration — the proper baseline that auto-mined libraries should match.
The manual_11 recipe at neighbouring k values. Same "top-k by quality_score" rule, but k = 10 / 12 / 13 instead of 11. Tests whether the smart dedup recipe is robust to small k changes, or accidental at k = 11.
For each trial we report whether its final attempt succeeded (the definition used in summaries.txt). Counting trial directories directly over-counts: a trial with multiple sandbox attempts can have one success even when its final attempt fails. All numbers in this paper use the same definition.
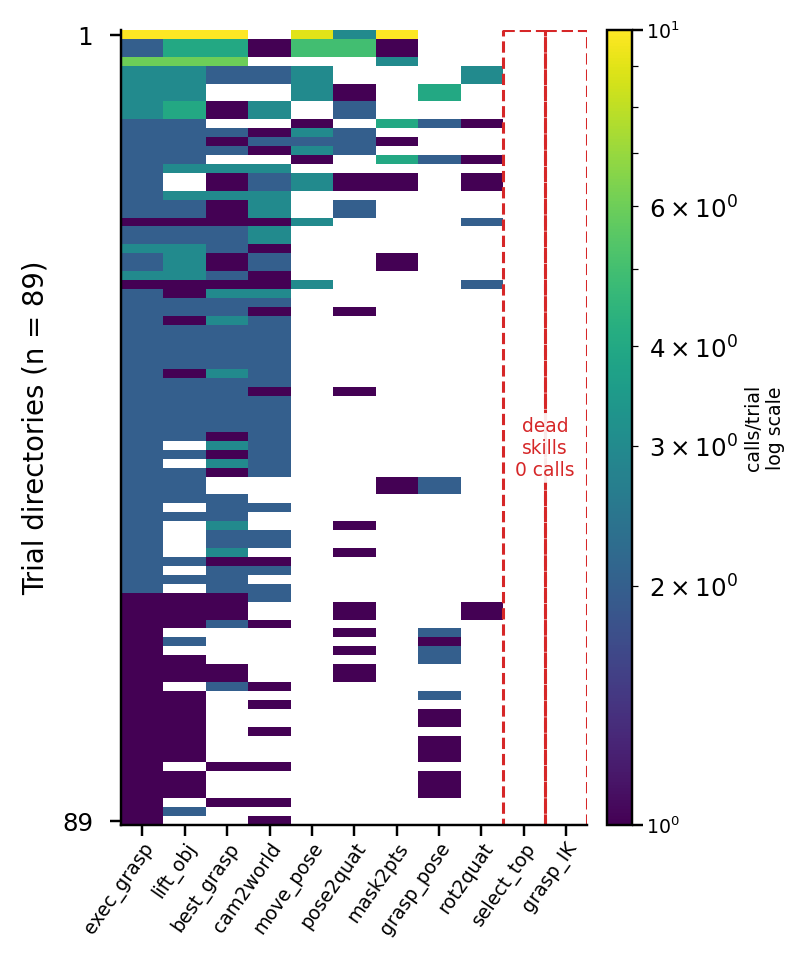
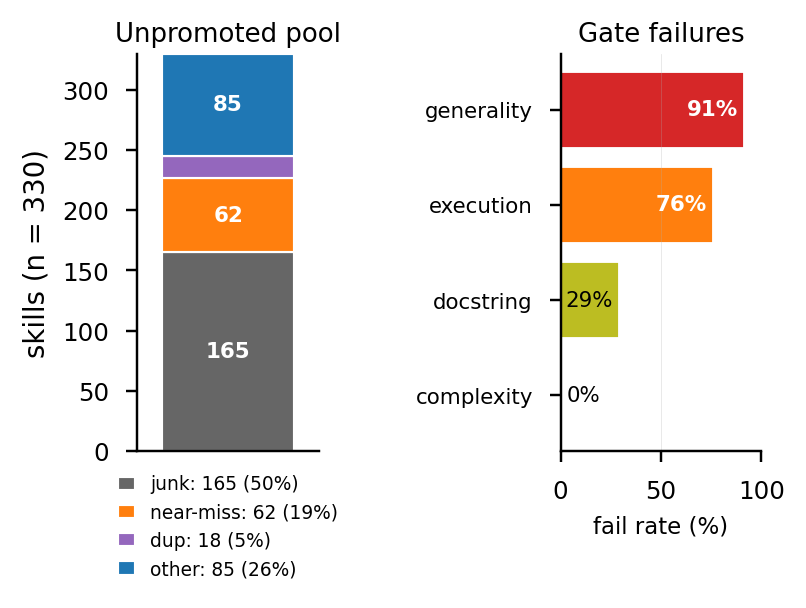
Left: top-4 of 11 promoted skills = 76% of calls; two dead skills (no docstring). Right: 330 unpromoted candidates, 91% fail the generality gate; 18 share a structural hash with a promoted skill.
The mining loop works: from a single trial corpus we end up with a small library where heavy-tailed usage is concentrated on a handful of skills with correct call signatures. Extraction is the easy part. Whether the resulting library actually helps is Q2.
The central question. We split it into four sub-questions: (a) within-task, (b) across LLM backbones, (c) across tasks, (d) sensitivity to the dedup algorithm.
| Condition | n | Success | Wilson 95% CI | vs P21_a |
|---|---|---|---|---|
P21_a | 50 | 39/50 = 78.0% | [64.8, 87.2] | (reference) |
C1 | 70 | 67/70 = 95.7% | [88.1, 98.5] | +18pp ✅ |
C2 | 70 | 68/70 = 97.1% | [90.2, 99.2] | +19pp ✅ |
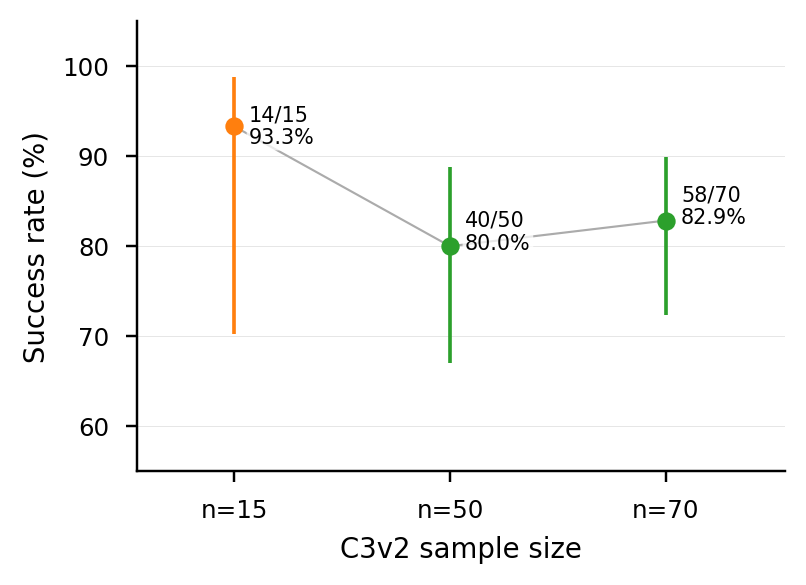
C3v2 | 70 | 58/70 = 82.9% | [72.4, 89.9] | +5pp (CI overlap) |
manual_11 | 70 | 66/70 = 94.3% | [86.2, 97.8] | +16pp ✅ |
nvidia9 NVIDIA published | 50 | 45/50 = 90.0% | [78.6, 95.7] | +12pp (CI overlap w/ C2) |
empty_ns | 30 | 13/30 = 43.3% | [27.4, 60.8] | −35pp |
The "ship this" arm: namespace seeding + gates + no structural dedup.
Baseline succeeds 78% of the time; the library effect needs n to detect.
22% baseline failures leave headroom for the library.
| Backbone | No helpers (P21_a) | NVIDIA-9 (manual) | Auto-mined (manual_11 / C2) | Auto vs NVIDIA-9 |
|---|---|---|---|---|
| gpt-4.1 | 78.0% [64.8, 87.2] | 90.0% [78.6, 95.7] | 97.1% [90.2, 99.2] (C2) | +7pp directional; CI overlap → O1 parity |
| Claude Sonnet 4 | 86.0% | — (not run) | 98.0% | — |
| DeepSeek v3 | 6.0% [2.1, 16.2] | 84.0% [71.5, 91.7] | 94.0% [83.8, 97.9] (manual_11) | +10pp directional; CI overlap → O1 parity |
Wilson CI overlap: gpt-4.1 NVIDIA-9 [78.6, 95.7] ∩ C2 [90.2, 99.2] = [90.2, 95.7]. DeepSeek NVIDIA-9 [71.5, 91.7] ∩ manual_11 [83.8, 97.9] = [83.8, 91.7]. One-sided binomial p=0.015 (gpt-4.1) and p=0.009 (DeepSeek) indicate directional signal but at n=50 the gaps sit inside the CI overlap — pre-registered O1 outcome.
| Condition | n | Task completed | Avg reward | Code blocks | Regenerations |
|---|---|---|---|---|---|
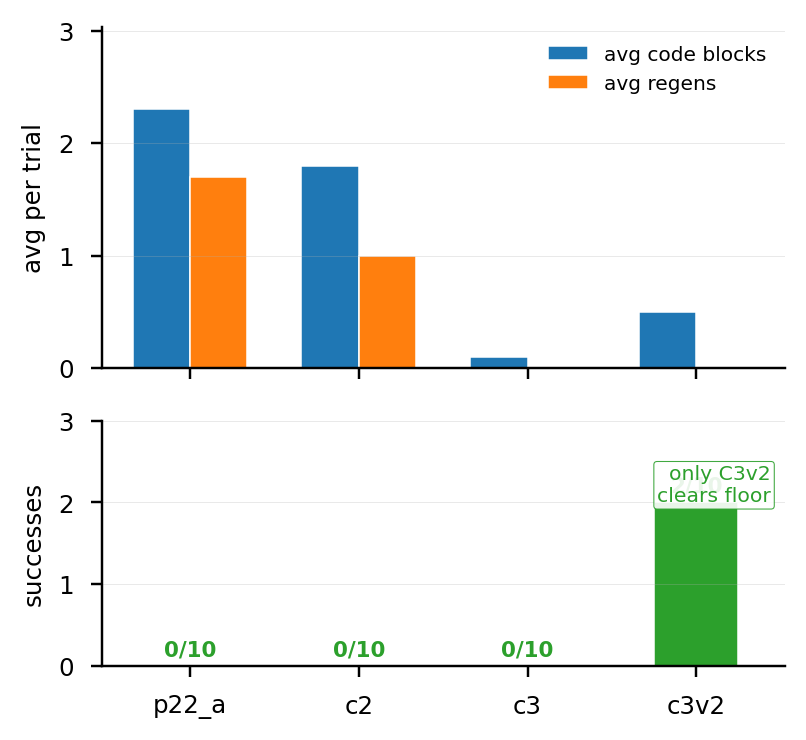
p21_a | 15 | 0/15 (0%) | 0.040 | 5.733 | 4.733 |
manual_11 | 15 | 0/15 (0%) | 0.060 | 4.133 | 3.133 |
Floor on both arms. All three cubes are present in the simulator (verified by sim.data.xpos), but SAM3 segmentation produces highly fragmented masks (200+ entries per cube) on multi-cube scenes — the downstream pose-from-mask functions get nothing usable.
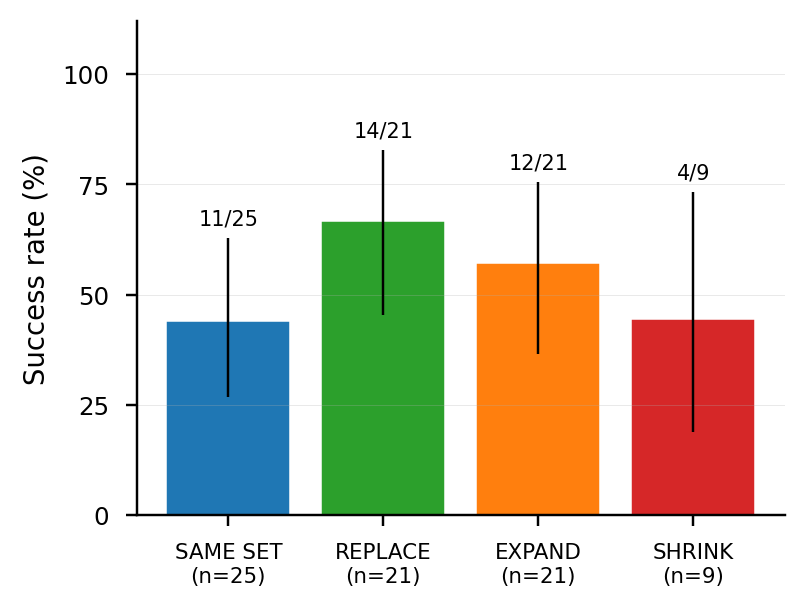
| k | n | Success | vs C3v2 (82.9%) |
|---|---|---|---|
| k=10 | 70 | 64/70 = 91.4% | marginal (P=0.034) |
| k=11 (manual_11) | 70 | 66/70 = 94.3% | separated (P=10⁻³) |
| k=12 | 70 | 61/70 = 87.1% | not separated (P=0.22, dip) |
| k=13 | 70 | 68/70 = 97.1% | separated (P=2×10⁻⁴) |
Within cube_lifting + no-dedup, the auto-mined library delivers a robust +18–19pp effect over the no-helpers baseline (P21_a), replicated across three backbones with magnitudes that scale inversely with baseline strength (Δ = +12 / +19 / +88pp). Production structural-hash dedup erases the gain. Cross-task transfer is gated by the vision pipeline, not the library.
NVIDIA-9 closure (Phase v12): In this single-task setting at n=50 each, auto-mined libraries reach Wilson 95% CIs that overlap NVIDIA's manually-curated 9-skill library on both backbones — gpt-4.1: NVIDIA-9 90.0% [78.6, 95.7] vs C2 97.1% [90.2, 99.2]; DeepSeek: NVIDIA-9 84.0% [71.5, 91.7] vs manual_11 94.0% [83.8, 97.9]. Auto-mined libraries trend ~7–10pp higher with directional binomial p<0.05 at n=50, but no pre-registered equivalence margin was set. The appropriate reading is therefore "failure to reject equality with a directional auto-mining advantage," not demonstrated equivalence. The pre-registered O1 boundary (gpt-4.1 ∈ [90%, 96%]; DeepSeek ∈ [70%, 90%]) is satisfied. The contribution is a feasibility result: in this single-task, reduced-API setting the auto-mining loop performs comparably to NVIDIA's manual offline curation. Stronger substitutability claims would require pre-registered equivalence-margin tests (TOST or Newcombe-score) and replication on tasks beyond cube_lifting.
code.py files contain no top-level def blocks. Given a dense library, the LLM composes API calls imperatively (pose = get_grasp_pose_for_mask(mask); execute_grasp(pose); ...) without wrapping anything in new helper functions. Round-2 = round-1; the trial sweep was skipped because it would replicate round-1 exactly.
def blocks. As library density grows, that assumption fails monotonically. cube_lifting under gpt-4.1 with k=12 is at or past saturation. The LLM is doing the right thing — there is no abstraction left to invent — but the mining pipeline cannot extract anything from this regime.
def-extraction with semantic-similarity clustering of frequently-co-occurring API-call sequences.
We measured a single snapshot. The round-2 saturation finding identifies a natural termination regime for the mining loop, but true long-horizon evolution dynamics (n=100–200 with library snapshots every N) remain unmeasured. This is the largest open question for paper v3.
Four evidence streams converge on a survival rule.
_undocumented is removed.(has_docstring, success_rate, name) should outperform structural-hash dedup — and it does (manual_11 vs C3v2 = +11pp).execute_grasp is invoked in 89/89 trial directories (universal). Long-tail skills appear only on retry. Two dead skills both lack docstrings and sit far down the call distribution.
execute_grasp failures get rewritten as move_to_pose_world + pose_matrix_to_pos_quat.
Skills survive when they are documented, sit at a pipeline hub, can be downgraded to primitives on retry, and substitute for weak self-correction in the host LLM. The production survivor rule should be (has_docstring, success_rate, name), not structural hash.
Open questions, organised by which RQ they map to.
| RQ | Limitation / open question | paper-v3 candidate |
|---|---|---|
| Q1 | Mining was run on cube_lifting only. Whether the same pipeline produces useful skills on harder tasks is not measurable until Q2c is unblocked. | Re-run mining on cube_stack_3 / LIBERO after the vision-pipeline upgrade. |
| Q2 | Cross-task transfer floors out (cube_stack_3 vision saturation; LIBERO floors even with privileged-API state). | Vision-pipeline upgrade: per-cube SAM with class anchors, contact-graspnet instance-aware pose, or grounded-segment-anything. cube_stack_3 floor → measurable transfer regime. |
| Q3 | Single-snapshot only. The saturation finding is a boundary, not an evolution measurement. | Long-horizon Q3: n=100–200 trials with library snapshots every N. Or round-2 mining on a harder task (saturation sidestep). |
| Q4 | The self-correction substitute mechanism is a falsifiable hypothesis we did not yet test. | DeepSeek iteration test: reflection-style regeneration prompting should reduce the +88pp library effect on DeepSeek if the mechanism is right. |
| General | cube_lifting's 90%+ rates may be a perception-easy ceiling; gpt-4.1 snapshot is unpinned (OpenRouter). | Harder baseline tasks (cube_stack 3+, NutAssembly), backbone snapshot pinning, variance characterisation. |
cube_lifting an automatic mining loop reaches performance comparable to NVIDIA's hand-curated 9-skill helpers (Wilson 95% CIs overlap; no equivalence margin pre-registered). The broader hypothesis behind this work is that the same self-improvement loop — discover useful subroutines from prior generations, accumulate them, re-apply them — is what would let a code-as-policy robot agent scale to a wider range of robot settings without humans hand-expanding the helper API. Testing that broader hypothesis is the paper-v3 program in the table above (vision-pipeline upgrade → re-mining on harder tasks → long-horizon evolution → equivalence-margin re-test). This paper is one piece of evidence on the way; it is not a cross-setting claim.