C2 success — no-dedup library
"ship this" arm: namespace seeding + gates + no structural dedup.
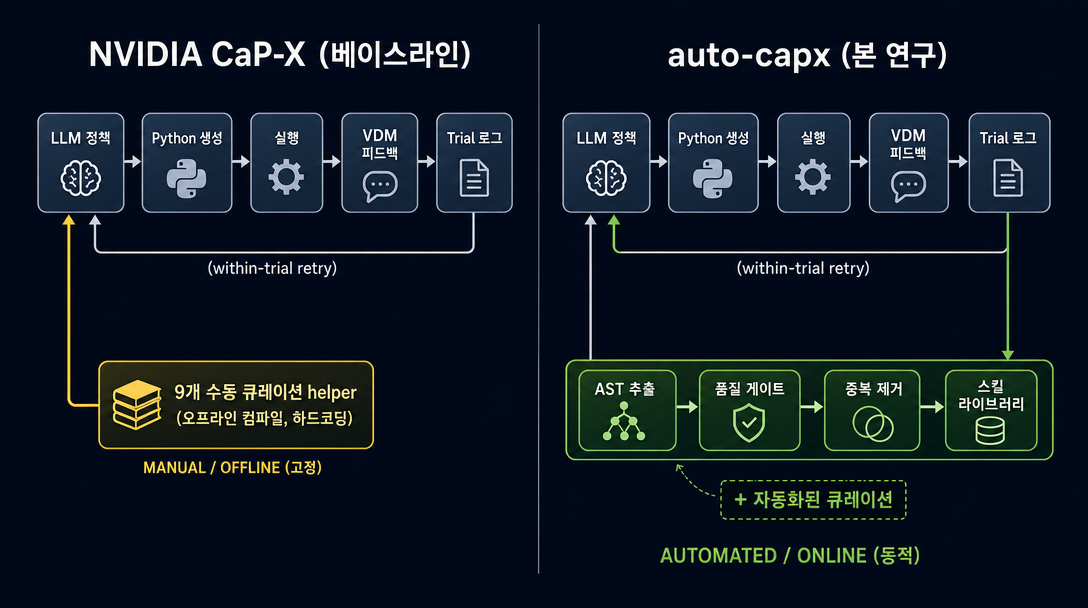
에이전트형 코딩 파이프라인 (Voyager, SWE-agent, OpenHands 등) 은 같은 작업을 반복할수록 자기가 만든 코드에서 쓸 만한 함수를 추출 → 라이브러리로 쌓아 → 다음 번에 재활용 하는 자기개선 루프를 공통으로 가지고 있습니다. NVIDIA CaP-X 도 이미 skill library 를 가지고 있지만 그 helper 들은 연구자(사람) 가 직접 큐레이션 한 것입니다. auto-capx (이 연구) 는 그 자기개선 루프를 CaP-X 위에 얹어, 자동 mining loop 가 NVIDIA 의 수동 큐레이션을 같은 수준으로 수행 하거나 일부 조건에서 더 잘 할 수 있는지 를 단일 task 에서 검증합니다. 이 연구가 가리키는 큰 그림: 더 일반적인 환경의 로봇이 사람이 helper API 를 손으로 늘려주지 않아도 code-as-policy 를 스스로 잘 적용하는 방향. 현재 증거는 단일 task / reduced-API 한정이며, cross-setting 일반화는 아직 검증되지 않았습니다. 4 가지 research question: 추출(extract) → 유용성(useful) → 진화(evolve) → 생존(survive).
상태: paper v12 · NVIDIA-9 closure 통합 · arXiv 제출 tar 151 KB · 누적 비용 ~$261.
NVIDIA CaP-X 는 LLM 에게 base API + 연구자가 손으로 고른 helper skill 셋 (FrankaControlApiReducedSkillLibrary, S3 published configuration 의 9 함수) 을 주고 robot 제어 Python 을 작성하게 합니다. helper 9 개는 NVIDIA 저자들이 수백 trial 에서 ~182 개 함수 → ~73 후보 → 사람이 9 개 선별한 것. auto-capx (이 연구) 는 그 위에 에이전트형 자기개선 루프를 얹습니다 — 이전 generation 에서 유용한 함수를 mine → gate → dedup → 다음 trial 에 재주입 — 그리고 그 자동 루프가 NVIDIA 의 수동 큐레이션과 reduced-API setting 에서 비슷한 수준의 성능을 낼 수 있는지 검증합니다 (trial Python parsing → quality gate 통과 → (선택적) dedup → 다음 trial 의 prompt + execution namespace 에 재주입, *no human in the loop*). 이 연구의 큰 그림: 사람이 helper API 를 손으로 늘려주지 않아도 code-as-policy 로봇이 더 다양한 환경에 스스로 적응하는 방향. 아래 diagram 이 큐레이션 차이를 보여주고, 실험은 auto-mined library variants 를 nvidia9 (NVIDIA 의 published 9-skill 라이브러리, 적절한 baseline) 와 P21_a (helpers 모두 ablate, "+pp" 기준점) 와 비교합니다.
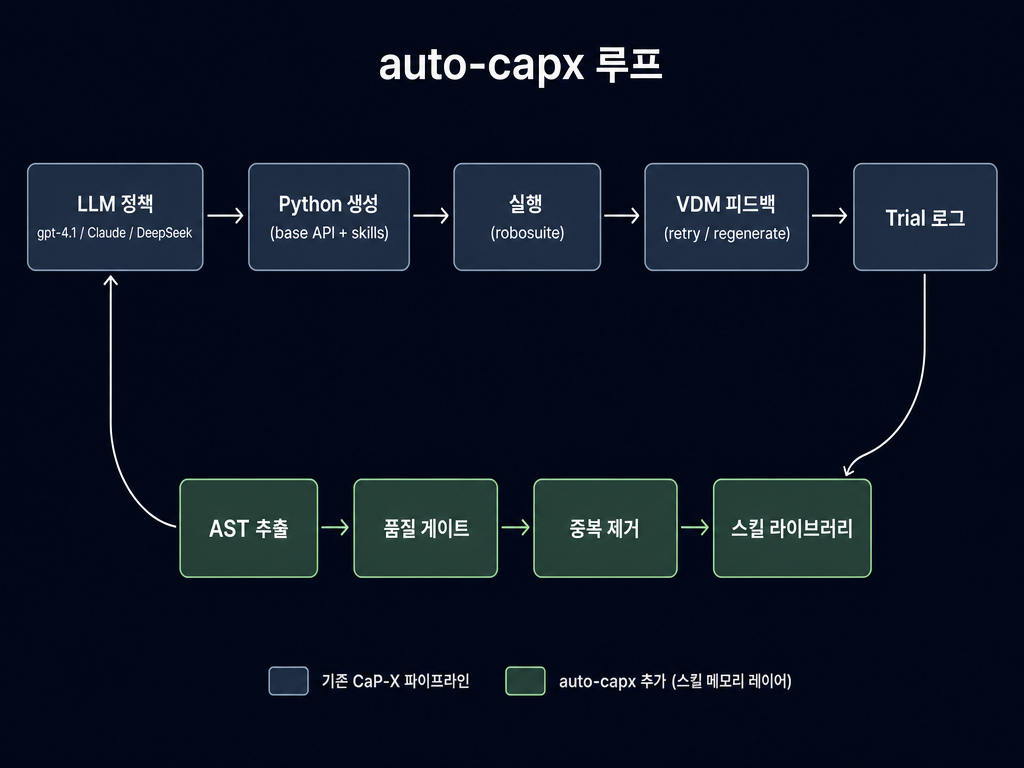
두 setup 모두 within-trial loop 공유 (LLM → Python → execute → VDM → retry). auto-capx 는 아래 줄 추가: trial logs 에서 재사용 가능한 함수 추출, gate, dedup → 그 library 를 LLM 의 namespace 에 reinject. 본 paper 의 모든 ablation 이 *그 아래 줄* 의 효과를 측정.
각 카드는 *library 안에 무엇이 있는지*, *어떤 가설을 검증하는지*, *왜 의미가 있는지* 를 설명합니다. 가장 중요한 숫자는 library size — dedup 이야기 (Q2d) 의 핵심은 *같은 size 의 두 library 가 다르게 작동하는가* 이기 때문입니다.
비교의 기준점. 로봇 코드 에이전트가 base CaP-X-style API 만 사용 — mined skill 0 개. 이외의 모든 condition (P21_a 의 n=50 성공률 78.0%) 이 여기에 비교됨.
quality gate 통과한 모든 함수, dedup 없음. 16 mined functions 가 prompt + execution namespace 에 주입. Namespace seeding (promoted skill 이 dependency 찾을 수 있게 하는 runtime fix) 활성.
quality-gated 14 skills, dedup 없음. C1 에서 가장 약한 2개 skill 제거. paper 가 production 으로 권장하는 arm ("namespace seeding + gates + no structural dedup").
C2 + structural-hash dedup. 현재 production survivor rule 이 함수를 AST hash 로 cluster 하고 cluster 당 하나만 keep. Library size 가 11 로 축소. 결과: 이 arm 이 no-skill baseline 과 통계적으로 동등 — paper 의 핵심 counter-evidence.
같은 11 size, structure 가 아니라 quality_score 로 선택. C2 의 14 skills 를 quality_score desc 로 정렬, top-11 keep (가장 약한 3개 drop). C3v2 와 size 같지만 survivor 다름.
16 함수 signature 와 empty body (pass). LLM 이 보는 typed namespace 는 C1 과 동일, 단 실행 가능한 body 가 없음. 질문: typed scaffolding 자체가 효과의 source 인가?
NVIDIA 가 직접 큐레이션한 9-skill 라이브러리. FrankaControlApiReducedSkillLibrary 클래스 메서드로 하드코딩되어 있음. 9 helper 는 NVIDIA 저자들이 수백 트라이얼에서 ~182 개 함수 → ~73 후보 → 사람이 9 개 선별. NVIDIA 의 published S3 configuration — auto-mined 라이브러리가 맞춰야 할 적절한 baseline.
manual_11 recipe 를 인접한 k 값에서 적용. 같은 "top-k by quality_score" rule, k = 10 / 12 / 13. Smart dedup recipe 가 작은 k 변경에 robust 한지, 아니면 k=11 의 우연인지 검증.
각 trial 의 final attempt 가 success 했는지 (summaries.txt 의 정의). Trial directory count 직접 분석은 over-counting — multiple sandbox attempts 중 *어떤 것이라도* success 면 통과로 잘못 계산. paper 의 모든 numbers 가 같은 metric 으로 통일됨.
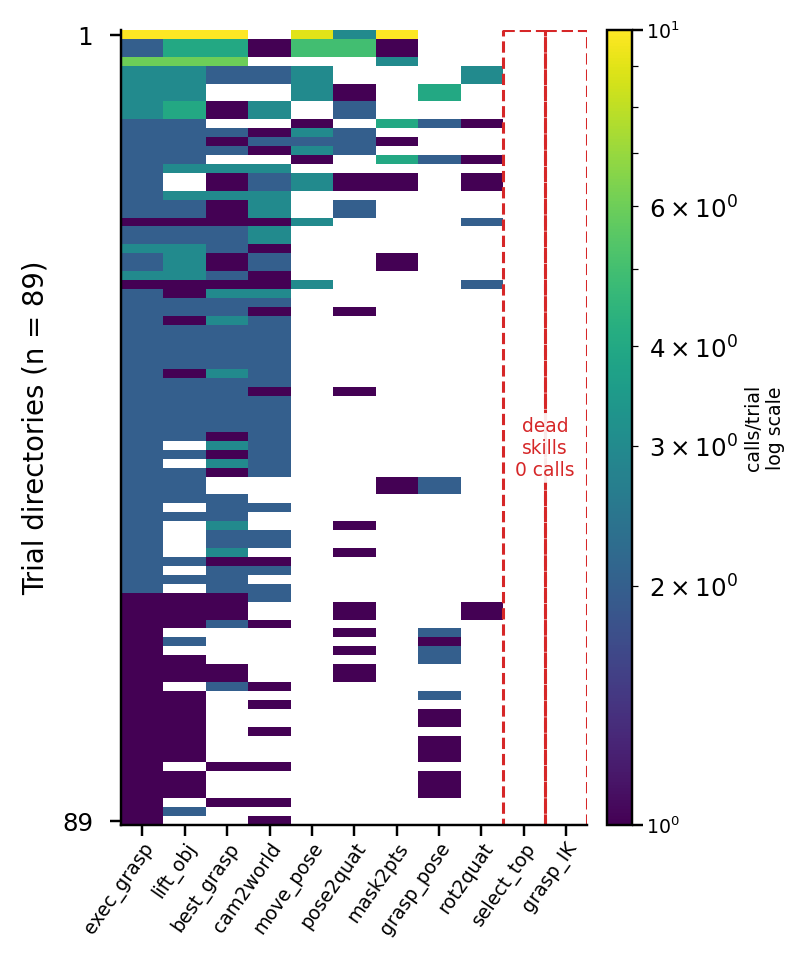
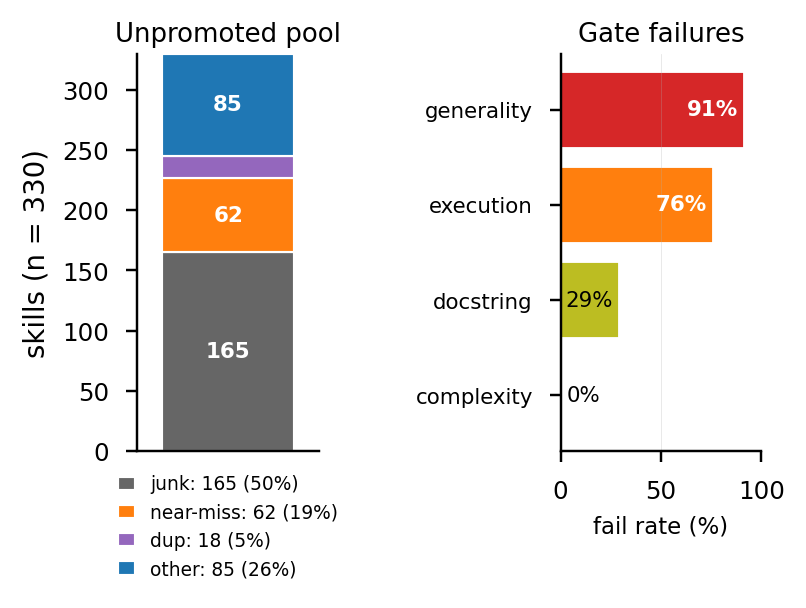
왼쪽: 11 promoted skills 중 top-4 = 호출의 76%; 2 dead skills (no docstring). 오른쪽: 330 unpromoted candidates, 91% 가 generality gate fail; 18개가 promoted skill 과 structural hash 일치.
Mining loop 는 작동: single trial corpus 에서 시작해 heavy-tailed 호출 분포의 small library 와 정확한 call signature 도출. 추출 자체는 쉬운 부분. 결과 library 가 실제 도움이 되는지는 Q2.
auto-capx 의 핵심 question. 4 sub-question 으로 분해: (a) within-task, (b) across LLM backbones, (c) across tasks, (d) dedup algorithm sensitivity.
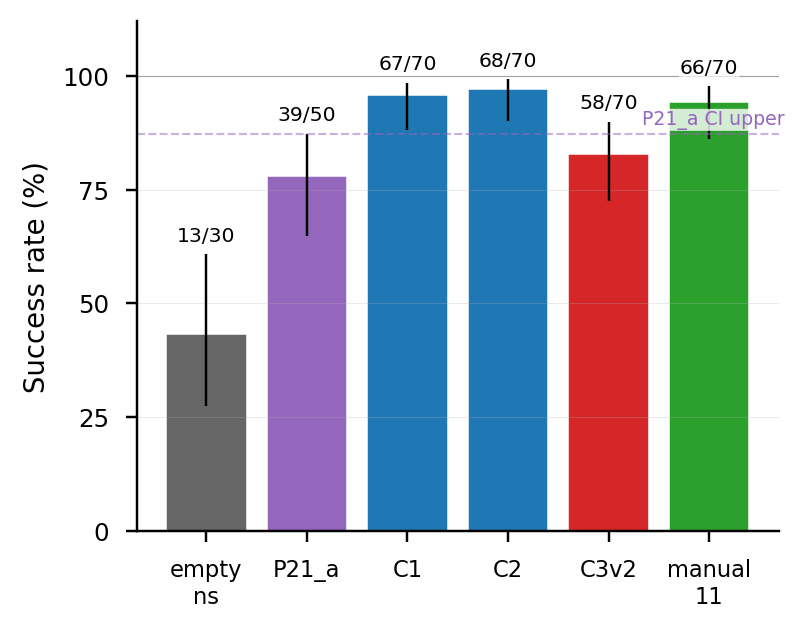
| Condition | n | 성공률 | Wilson 95% CI | vs P21_a |
|---|---|---|---|---|
P21_a | 50 | 39/50 = 78.0% | [64.8, 87.2] | (reference) |
C1 | 70 | 67/70 = 95.7% | [88.1, 98.5] | +18pp ✅ |
C2 | 70 | 68/70 = 97.1% | [90.2, 99.2] | +19pp ✅ |
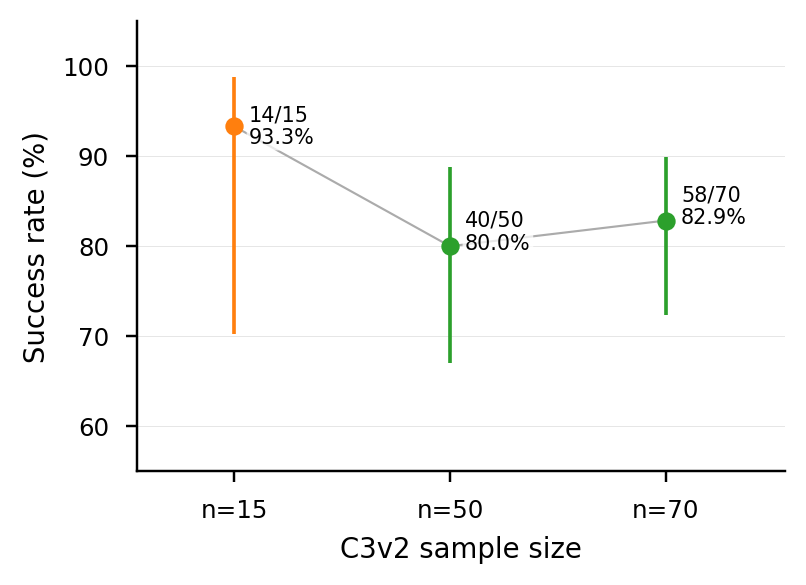
C3v2 | 70 | 58/70 = 82.9% | [72.4, 89.9] | +5pp (CI overlap) |
manual_11 | 70 | 66/70 = 94.3% | [86.2, 97.8] | +16pp ✅ |
nvidia9 NVIDIA published | 50 | 45/50 = 90.0% | [78.6, 95.7] | +12pp (CI overlap w/ C2) |
empty_ns | 30 | 13/30 = 43.3% | [27.4, 60.8] | −35pp |
"ship this" arm: namespace seeding + gates + no structural dedup.
Baseline 78% 성공률 — library 효과 detect 하려면 n 필요.
22% baseline 실패 — library 효과의 측정 가능 영역.
| Backbone | No helpers (P21_a) | NVIDIA-9 (수동) | Auto-mined (manual_11 / C2) | Auto vs NVIDIA-9 |
|---|---|---|---|---|
| gpt-4.1 | 78.0% [64.8, 87.2] | 90.0% [78.6, 95.7] | 97.1% [90.2, 99.2] (C2) | +7pp 방향성; CI overlap → O1 parity |
| Claude Sonnet 4 | 86.0% | — (미실행) | 98.0% | — |
| DeepSeek v3 | 6.0% [2.1, 16.2] | 84.0% [71.5, 91.7] | 94.0% [83.8, 97.9] (manual_11) | +10pp 방향성; CI overlap → O1 parity |
Wilson CI overlap: gpt-4.1 NVIDIA-9 [78.6, 95.7] ∩ C2 [90.2, 99.2] = [90.2, 95.7]. DeepSeek NVIDIA-9 [71.5, 91.7] ∩ manual_11 [83.8, 97.9] = [83.8, 91.7]. One-sided binomial p=0.015 (gpt-4.1), p=0.009 (DeepSeek) — 방향성 신호 있으나 n=50 에서 CI overlap 범위 내 → 사전등록 O1 outcome.
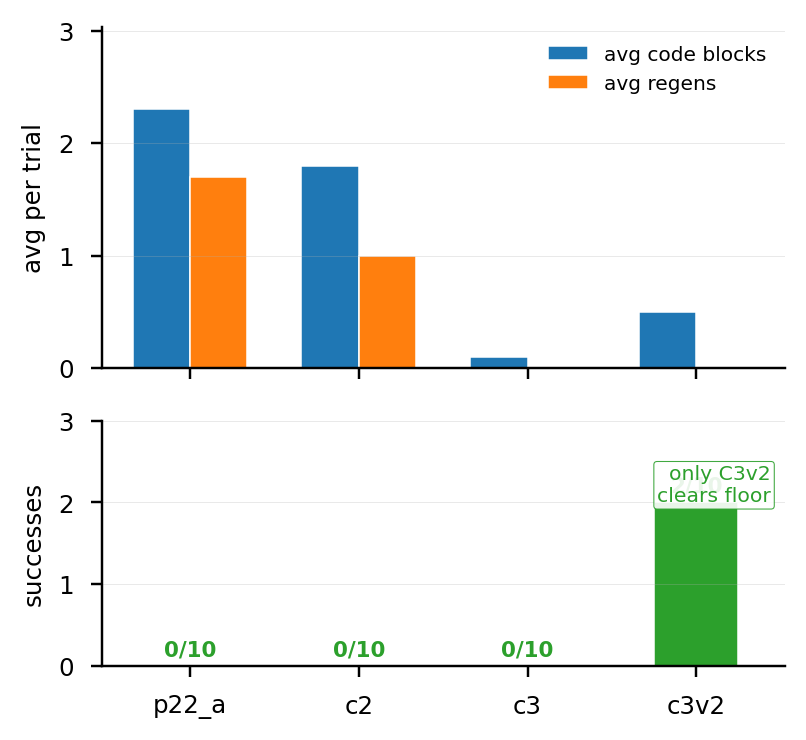
| Condition | n | Task completed | Avg reward | Code blocks | Regenerations |
|---|---|---|---|---|---|
p21_a | 15 | 0/15 (0%) | 0.040 | 5.733 | 4.733 |
manual_11 | 15 | 0/15 (0%) | 0.060 | 4.133 | 3.133 |
두 arm 모두 floor. 3개 큐브 모두 simulator 에 실재 (sim.data.xpos 직접 verify), 단 SAM3 segmentation 이 multi-cube scene 에서 fragmented mask (cube 당 200+ entries) 생성 → downstream pose-from-mask 함수가 사용 가능한 mask 없음.
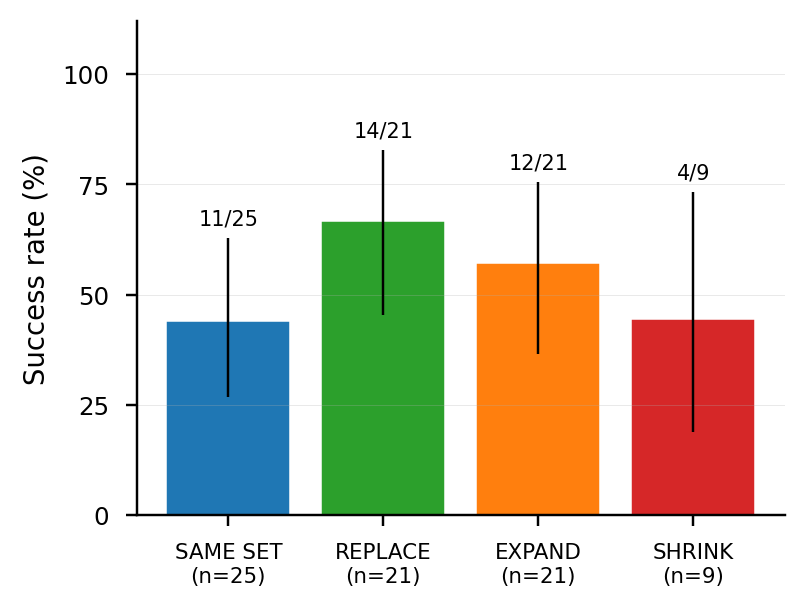
| k | n | 성공률 | vs C3v2 (82.9%) |
|---|---|---|---|
| k=10 | 70 | 64/70 = 91.4% | marginal (P=0.034) |
| k=11 (manual_11) | 70 | 66/70 = 94.3% | separated (P=10⁻³) |
| k=12 | 70 | 61/70 = 87.1% | not separated (P=0.22, dip) |
| k=13 | 70 | 68/70 = 97.1% | separated (P=2×10⁻⁴) |
cube_lifting + no-dedup 안에서 auto-mined library 는 no-helpers baseline (P21_a) 대비 robust +18~19pp 효과, 3 backbone 에 걸쳐 baseline 약함과 inversely 비례하는 magnitude (Δ = +12 / +19 / +88pp). Production structural-hash dedup 은 효과 erase. Cross-task transfer 는 vision pipeline 에 막혀 있음.
NVIDIA-9 closure (Phase v12): 단일 task n=50 setting 에서 auto-mining 의 Wilson 95% CI 가 NVIDIA 의 수동 큐레이션 9-skill 라이브러리와 overlap — gpt-4.1: NVIDIA-9 90.0% [78.6, 95.7] vs C2 97.1% [90.2, 99.2]; DeepSeek: NVIDIA-9 84.0% [71.5, 91.7] vs manual_11 94.0% [83.8, 97.9]. Auto-mined 라이브러리가 ~7~10pp 높은 방향성, directional binomial p<0.05 (n=50). Equivalence margin 은 사전등록 안 됨 → "방향성 auto-mining 우위, 단 동등성 미입증 (failure to reject equality)" 이 정확한 해석이며 demonstrated equivalence 아님. 사전등록 O1 boundary (gpt-4.1 ∈ [90%, 96%]; DeepSeek ∈ [70%, 90%]) 는 만족. 본 연구의 기여는 feasibility 결과: 단일 task / reduced-API setting 에서 auto-mining loop 가 NVIDIA 의 오프라인 수동 큐레이션과 비슷한 수준의 성능에 도달함. 강한 substitutability claim 은 사전등록된 equivalence margin (TOST 또는 Newcombe-score) 과 cube_lifting 외 task replication 이 필요.
code.py 들에 top-level def block 0 개. Dense library 받으면 LLM 이 API call 을 imperative 하게 composes (pose = get_grasp_pose_for_mask(mask); execute_grasp(pose); ...), 새 helper function 만들지 않음. Round-2 = round-1; trial sweep skip (round-1 의 replication 만 됨).
def block 들어있다". Library density 늘면 이 가정 monotonic 하게 fail. cube_lifting × gpt-4.1 × k=12 는 saturation point 에 있거나 그 이상. LLM 의 *correct behavior* — 새로 만들 abstraction 없음 — 이지만 mining pipeline 이 이 regime 에서 추출 못함.
def-extraction 을 frequently-co-occurring API-call sequence 의 semantic-similarity clustering 으로 replace.
Single snapshot 만 측정. Round-2 saturation finding 은 mining loop 의 *natural termination regime* 발견 — but true long-horizon evolution dynamics (n=100-200 with library snapshots every N) 는 unmeasured. Paper v3 의 가장 큰 open question.
survival rule 의 4 evidence stream 이 converge.
_undocumented 변수명 confound 제거.(has_docstring, success_rate, name) 가 structural-hash dedup 보다 좋음 — manual_11 vs C3v2 = +11pp 입증.execute_grasp 는 89/89 trial directories 에서 호출 (universal). Long-tail skill 은 retry 시에만 등장. 2 dead skills 모두 docstring 없음 + call 분포의 far down.
execute_grasp fail → move_to_pose_world + pose_matrix_to_pos_quat 로 분해.
Skill 은 다음 시 살아남음: documented; pipeline hub 위치; retry 시 primitive 로 downgrade 가능; host LLM 의 weak self-correction 을 substitute. Production survivor rule = (has_docstring, success_rate, name), structural hash 아님.
Open question 들을 mapping 되는 RQ 별로 정리.
| RQ | 한계 / open question | paper-v3 candidate |
|---|---|---|
| Q1 | cube_lifting 에서만 mining 진행. 다른 task 에서 같은 pipeline 이 useful skill 산출하는지는 Q2c unblock 까지 unmeasurable. | Vision pipeline 수정 후 cube_stack_3 / LIBERO 에서 mining 재실행. |
| Q2 | Cross-task transfer floor (cube_stack_3 vision saturation; LIBERO 도 privileged-API 도 floor). | Vision pipeline upgrade: per-cube SAM with class anchors, contact-graspnet instance-aware pose, 또는 grounded-segment-anything. cube_stack_3 floor → measurable transfer regime. |
| Q3 | Single snapshot only. Saturation finding 은 boundary, evolution measurement 아님. | Long-horizon Q3: n=100-200 trials with library snapshots every N. 또는 round-2 mining on harder task (saturation sidestep). |
| Q4 | Self-correction substitute mechanism = falsifiable hypothesis 인데 본 phase 에서 test 안 함. | DeepSeek iteration test: reflection-style regeneration prompting 으로 +88pp library effect 감소 예측 검증. |
| 일반 | cube_lifting 의 90%+ rates 가 perception-easy ceiling 일 수 있음; gpt-4.1 snapshot 미pin (OpenRouter). | 더 어려운 baseline task (cube_stack 3+, NutAssembly), backbone snapshot pinning, variance characterization. |
cube_lifting) 한정입니다 — 자동 mining loop 가 NVIDIA 의 수동 9-skill helper 와 Wilson 95% CI overlap 수준 (equivalence margin 미사전등록). 이 작업이 가리키는 더 큰 가설은 같은 자기개선 루프 (이전 generation 에서 유용한 함수 발견 → 누적 → 재활용) 가 사람이 helper API 를 손으로 늘려주지 않아도 code-as-policy 로봇이 더 다양한 환경에 스스로 적응 하도록 도울 수 있다는 것입니다. 그 broader hypothesis 검증은 위 표의 paper-v3 program (vision pipeline 업그레이드 → 더 어려운 task 에서 re-mining → long-horizon evolution → equivalence-margin 재검증) 입니다. 본 paper 는 그 과정의 한 evidence piece 이며, cross-setting claim 자체는 아닙니다.