Deepseek OCR App
Quick vibe coded app for DeepSeek OCR
AI-Agent Assisted
Tier 2README
🚀 DeepSeek OCR - React + FastAPI
Modern OCR web application powered by DeepSeek-OCR with a stunning React frontend and FastAPI backend. Now with PDF processing and multi-format document conversion!
✨ What's New in v2.2.0 - PDF Processing & Document Conversion
We've added powerful PDF processing capabilities based on community feedback! Here's what you can do now:
📄 Process Entire PDF Documents
- Upload PDF files up to 100MB
- Automatic multi-page OCR processing
- Real-time progress tracking for large documents
- Extract text from scanned PDFs or image-based documents
🔄 Convert to Multiple Formats
Export your OCR results in the format you need:
- Markdown (.md) - Clean, structured text perfect for documentation
- HTML (.html) - Styled documents with embedded images and tables
- Word (.docx) - Professional documents with formatting, tables, and images
- JSON - Structured data for programmatic access
🖼️ Automatic Image Extraction
- Detects and extracts images from PDF pages
- Embeds images in exported documents
- Preserves image placement and context
📐 Formula & Formatting Preservation
- Maintains mathematical formulas (LaTeX syntax)
- Preserves tables, headings, and document structure
- Cleans up special characters while keeping formatting intact
🎯 Use Cases
- Document Digitization - Convert scanned PDFs to editable formats
- Data Extraction - Pull structured data from forms and invoices
- Content Migration - Convert PDFs to Markdown for wikis/documentation
- Academic Papers - Extract text and formulas from research papers
- Business Documents - Convert reports to Word for editing
Latest Updates (v2.2.0) - November 2025
- 🎉 NEW: PDF Processing - Upload PDFs and extract text from all pages
- 🎉 NEW: Multi-Format Export - Convert to Markdown, HTML, DOCX, or JSON
- 🎉 NEW: Automatic Image Extraction - Extract and preserve images from PDFs
- 🎉 NEW: Progress Tracking - Real-time progress for multi-page documents
- ✅ Dual mode: Image OCR + PDF Processing with format conversion
- ✅ Enhanced document processing with formula and formatting preservation
Previous Updates (v2.1.1)
- ✅ Fixed image removal button - now properly clears and allows re-upload
- ✅ Fixed multiple bounding boxes parsing - handles
[[x1,y1,x2,y2], [x1,y1,x2,y2]]format- ✅ Simplified to 4 core working modes for better stability
- ✅ Fixed bounding box coordinate scaling (normalized 0-999 → actual pixels)
- ✅ Fixed HTML rendering (model outputs HTML, not Markdown)
- ✅ Increased file upload limit to 100MB (configurable)
- ✅ Added .env configuration support
Quick Start
-
Clone and configure:
git clone <repository-url> cd deepseek_ocr_app # Copy and customize environment variables cp .env.example .env # Edit .env to configure ports, upload limits, etc. -
Start the application:
docker compose up --buildThe first run will download the model (~5-10GB), which may take some time.
-
Access the application:
- Frontend: http://localhost:3000 (or your configured FRONTEND_PORT)
- Backend API: http://localhost:8000 (or your configured API_PORT)
- API Docs: http://localhost:8000/docs
🎓 How to Use
Processing Images (Single Image OCR)
- Select "Image OCR" mode in the toggle
- Upload an image (PNG, JPG, WEBP, etc.)
- Choose your OCR mode:
- Plain OCR - Extract all text
- Describe - Get image description
- Find - Locate specific terms
- Freeform - Use custom prompts
- Click "Analyze Image"
- View results with bounding boxes (if enabled)
- Copy or download the extracted text
Processing PDFs (Multi-Page Documents) - NEW!
- Select "PDF Processing" mode in the toggle
- Upload a PDF file (up to 100MB)
- Choose your OCR mode (same as above)
- Select output format:
- 📝 Markdown - For documentation, wikis, GitHub
- 🌐 HTML - For web publishing, styled viewing
- 📄 DOCX - For Word editing, professional documents
- 📊 JSON - For programmatic access, data extraction
- Click "Process PDF"
- Watch the progress bar as pages are processed
- Your file downloads automatically when complete!
Tips for Best Results
- For scanned documents: Use higher DPI (144-300) in advanced settings
- For tables: The model excels at extracting structured data
- For formulas: Mathematical notation is preserved in output
- For images in PDFs: Enable "Extract Images" to include them in output
- For large PDFs: JSON format is fastest, DOCX takes longer due to formatting
Output Format Comparison
| Format | Best For | Features | File Size |
|---|---|---|---|
| Markdown | Documentation, GitHub, wikis | Clean text, tables, code blocks | Smallest |
| HTML | Web viewing, sharing | Styled output, embedded images, tables | Medium |
| DOCX | Editing, professional docs | Full formatting, images, tables | Largest |
| JSON | Data processing, APIs | Structured data, metadata, page info | Small |
Features
Dual Processing Modes
📸 Image OCR (4 Core Modes)
- Plain OCR - Raw text extraction from any image
- Describe - Generate intelligent image descriptions
- Find - Locate specific terms with visual bounding boxes
- Freeform - Custom prompts for specialized tasks
📄 PDF Processing (NEW!)
- Multi-Page Processing - Process entire PDF documents page by page
- Format Conversion - Export to Markdown, HTML, DOCX, or JSON
- Image Extraction - Automatically extract and preserve embedded images
- Formula Preservation - Maintain mathematical formulas and special formatting
- Progress Tracking - Real-time progress updates for large documents
UI Features
- 🎨 Glass morphism design with animated gradients
- 🎯 Drag & drop file upload (Images up to 10MB, PDFs up to 100MB)
- 🔄 Easy file removal and re-upload
- 📦 Grounding box visualization with proper coordinate scaling
- ✨ Smooth animations (Framer Motion)
- 📋 Copy/Download results in multiple formats
- 🎛️ Advanced settings dropdown
- 📝 HTML and Markdown rendering for formatted output
- 🔍 Multiple bounding box support (handles multiple instances of found terms)
- 📊 Progress bars for multi-page PDF processing
- 💾 Direct download for converted documents (MD, HTML, DOCX)
Configuration
The application can be configured via the .env file:
# API Configuration
API_HOST=0.0.0.0
API_PORT=8000
# Frontend Configuration
FRONTEND_PORT=3000
# Model Configuration
MODEL_NAME=deepseek-ai/DeepSeek-OCR
HF_HOME=/models
# Upload Configuration
MAX_UPLOAD_SIZE_MB=100 # Maximum file upload size
# Processing Configuration
BASE_SIZE=1024 # Base processing resolution
IMAGE_SIZE=640 # Tile processing resolution
CROP_MODE=true # Enable dynamic cropping for large images
Environment Variables
API_HOST: Backend API host (default: 0.0.0.0)API_PORT: Backend API port (default: 8000)FRONTEND_PORT: Frontend port (default: 3000)MODEL_NAME: HuggingFace model identifierHF_HOME: Model cache directoryMAX_UPLOAD_SIZE_MB: Maximum file upload size in megabytesBASE_SIZE: Base image processing size (affects memory usage)IMAGE_SIZE: Tile size for dynamic croppingCROP_MODE: Enable/disable dynamic image cropping
Tech Stack
Frontend
- Framework: React 18 + Vite 5
- Styling: TailwindCSS 3 + Custom Glass Morphism
- Animations: Framer Motion 11
- HTTP Client: Axios
- File Upload: React Dropzone
Backend
- API Framework: FastAPI (async Python web framework)
- ML/AI: PyTorch + Transformers 4.46 + DeepSeek-OCR
- PDF Processing: PyMuPDF (fitz) + img2pdf
- Document Conversion:
- python-docx (Word documents)
- markdown (Markdown processing)
- Custom HTML generator
- Configuration: python-decouple for environment management
Infrastructure
- Server: Nginx (reverse proxy & static file serving)
- Container: Docker + Docker Compose with multi-stage builds
- GPU: NVIDIA CUDA support (tested on RTX 3090, RTX 5090)
Project Structure
deepseek-ocr/
├── backend/ # FastAPI backend
│ ├── main.py # Main API with OCR and PDF endpoints
│ ├── pdf_utils.py # PDF processing utilities (NEW)
│ ├── format_converter.py # Document format conversion (NEW)
│ ├── requirements.txt
│ └── Dockerfile
├── frontend/ # React frontend
│ ├── src/
│ │ ├── components/
│ │ │ ├── ImageUpload.jsx # File upload (images & PDFs)
│ │ │ ├── PDFProcessor.jsx # PDF processing UI (NEW)
│ │ │ ├── ModeSelector.jsx
│ │ │ ├── ResultPanel.jsx
│ │ │ └── AdvancedSettings.jsx
│ │ ├── App.jsx # Main app with dual mode support
│ │ └── main.jsx
│ ├── package.json
│ ├── nginx.conf
│ └── Dockerfile
├── models/ # Model cache
└── docker-compose.yml
Development
Docker compose cycle to test:
docker compose down
docker compose up --build
Requirements
Hardware
- NVIDIA GPU with CUDA support
- Recommended: RTX 3090, RTX 4090, RTX 5090, or better
- Minimum: 8-12GB VRAM for the model
- More VRAM always good!
Software
-
Docker & Docker Compose (latest version recommended)
-
NVIDIA Driver - Installing NVIDIA Drivers on Ubuntu (Blackwell/RTX 5090)
Note: Getting NVIDIA drivers working on Blackwell GPUs can be a pain! Here's what worked:
The key requirements for RTX 5090 on Ubuntu 24.04:
- Use the open-source driver (nvidia-driver-570-open or newer, like nvidia-driver-580-open)
- Upgrade to kernel 6.11+ (6.14+ recommended for best stability)
- Enable Resize Bar in BIOS/UEFI (critical!)
Step-by-Step Instructions:
-
Install NVIDIA Open Driver (580 or newer)
sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update sudo apt remove --purge nvidia* sudo nvidia-installer --uninstall # If you have it sudo apt autoremove sudo apt install nvidia-driver-580-open -
Upgrade Linux Kernel to 6.11+ (for Ubuntu 24.04 LTS)
sudo apt install --install-recommends linux-generic-hwe-24.04 linux-headers-generic-hwe-24.04 sudo update-initramfs -u sudo apt autoremove -
Reboot
sudo reboot -
Enable Resize Bar in UEFI/BIOS
- Restart and enter UEFI (usually F2, Del, or F12 during boot)
- Find and enable "Resize Bar" or "Smart Access Memory"
- This will also enable "Above 4G Decoding" and disable "CSM" (Compatibility Support Module)—that's expected!
- Save and exit
-
Verify Installation
nvidia-smiYou should see your RTX 5090 listed!
💡 Why open drivers? I dunno, but the open drivers have better support for Blackwell GPUs. Without Resize Bar enabled, you'll get a black screen even with correct drivers!
Credit: Solution adapted from this Reddit thread.
-
NVIDIA Container Toolkit (required for GPU access in Docker)
System Requirements
- ~20GB free disk space (for model weights and Docker images)
- 16GB+ system RAM recommended
- Fast internet connection for initial model download (~5-10GB)
Known Issues & Fixes
✅ FIXED: Image removal and re-upload (v2.1.1)
- Issue: Couldn't remove uploaded image and upload a new one
- Fix: Added prominent "Remove" button that clears image state and allows fresh upload
✅ FIXED: Multiple bounding boxes (v2.1.1)
- Issue: Only single bounding box worked, multiple boxes like
[[x1,y1,x2,y2], [x1,y1,x2,y2]]failed - Fix: Updated parser to handle both single and array of coordinate arrays using
ast.literal_eval
✅ FIXED: Grounding box coordinate scaling (v2.1)
- Issue: Bounding boxes weren't displaying correctly
- Cause: Model outputs coordinates normalized to 0-999, not actual pixel dimensions
- Fix: Backend now properly scales coordinates using the formula:
actual_coord = (normalized_coord / 999) * image_dimension
✅ FIXED: HTML vs Markdown rendering (v2.1)
- Issue: Output was being rendered as Markdown when model outputs HTML
- Cause: Model is trained to output HTML (especially for tables)
- Fix: Frontend now detects and renders HTML properly using
dangerouslySetInnerHTML
✅ FIXED: Limited upload size (v2.1)
- Issue: Large images couldn't be uploaded
- Fix: Increased nginx
client_max_body_sizeto 100MB (configurable via .env)
⚠️ Simplified Mode Selection (v2.1.1)
- Change: Reduced from 12 modes to 4 core working modes
- Reason: Advanced modes (tables, layout, PII, multilingual) need additional testing
- Working modes: Plain OCR, Describe, Find, Freeform
- Future: Additional modes will be re-enabled after thorough testing
How the Model Works
Coordinate System
The DeepSeek-OCR model uses a normalized coordinate system (0-999) for bounding boxes:
- All coordinates are output in range [0, 999]
- Backend scales:
pixel_coord = (model_coord / 999) * actual_dimension - This ensures consistency across different image sizes
Dynamic Cropping
For large images, the model uses dynamic cropping:
- Images ≤640x640: Direct processing
- Larger images: Split into tiles based on aspect ratio
- Global view (BASE_SIZE) + Local views (IMAGE_SIZE tiles)
- See
process/image_process.pyfor implementation details
Output Format
- Plain text modes: Return raw text
- Table modes: Return HTML tables or CSV
- JSON modes: Return structured JSON
- Grounding modes: Return text with
<|ref|>label<|/ref|><|det|>[[coords]]<|/det|>tags
API Usage
POST /api/ocr
Parameters:
image(file, required) - Image file to process (up to 100MB)mode(string) - OCR mode:plain_ocr|describe|find_ref|freeformprompt(string) - Custom prompt for freeform modegrounding(bool) - Enable bounding boxes (auto-enabled for find_ref)find_term(string) - Term to locate in find_ref mode (supports multiple matches)base_size(int) - Base processing size (default: 1024)image_size(int) - Tile size for cropping (default: 640)crop_mode(bool) - Enable dynamic cropping (default: true)include_caption(bool) - Add image description (default: false)
Response:
{
"success": true,
"text": "Extracted text or HTML output...",
"boxes": [{"label": "field", "box": [x1, y1, x2, y2]}],
"image_dims": {"w": 1920, "h": 1080},
"metadata": {
"mode": "layout_map",
"grounding": true,
"base_size": 1024,
"image_size": 640,
"crop_mode": true
}
}
Note on Bounding Boxes:
- The model outputs coordinates normalized to 0-999
- The backend automatically scales them to actual image dimensions
- Coordinates are in [x1, y1, x2, y2] format (top-left, bottom-right)
- Supports multiple boxes: When finding multiple instances, format is
[[x1,y1,x2,y2], [x1,y1,x2,y2], ...] - Frontend automatically displays all boxes overlaid on the image with unique colors
POST /api/process-pdf (NEW!)
Process PDF documents with OCR and export to various formats.
Parameters:
pdf_file(file, required) - PDF file to process (up to 100MB)mode(string) - OCR mode:plain_ocr|describe|find_ref|freeformprompt(string) - Custom prompt for freeform modeoutput_format(string) - Output format:markdown|html|docx|jsongrounding(bool) - Enable bounding boxes (default: false)include_caption(bool) - Add image descriptions (default: false)extract_images(bool) - Extract embedded images from PDF (default: true)dpi(int) - PDF rendering resolution (default: 144)base_size(int) - Base processing size (default: 1024)image_size(int) - Tile size for cropping (default: 640)crop_mode(bool) - Enable dynamic cropping (default: true)
Response Formats:
JSON Format (output_format=json):
{
"success": true,
"total_pages": 5,
"pages": [
{
"page_number": 1,
"text": "Extracted and cleaned text...",
"raw_text": "Raw model output with tags...",
"boxes": [{"label": "field", "box": [x1, y1, x2, y2]}],
"images": ["base64_encoded_image_data..."],
"image_dims": {"w": 1920, "h": 1080}
}
],
"metadata": {
"mode": "plain_ocr",
"grounding": false,
"extract_images": true,
"dpi": 144
}
}
File Downloads (output_format=markdown|html|docx):
- Returns the document as a downloadable file
- Markdown:
.mdfile with preserved formatting - HTML:
.htmlfile with embedded styling and images - DOCX:
.docxWord document with tables and formatting
Features:
- 📄 Multi-page processing with progress tracking
- 🖼️ Automatic image extraction and embedding
- 📐 Formula and formatting preservation
- 🎨 Styled HTML output with tables and code blocks
- 📝 Clean Markdown with proper structure
- 📋 Professional DOCX with headings and tables
Examples
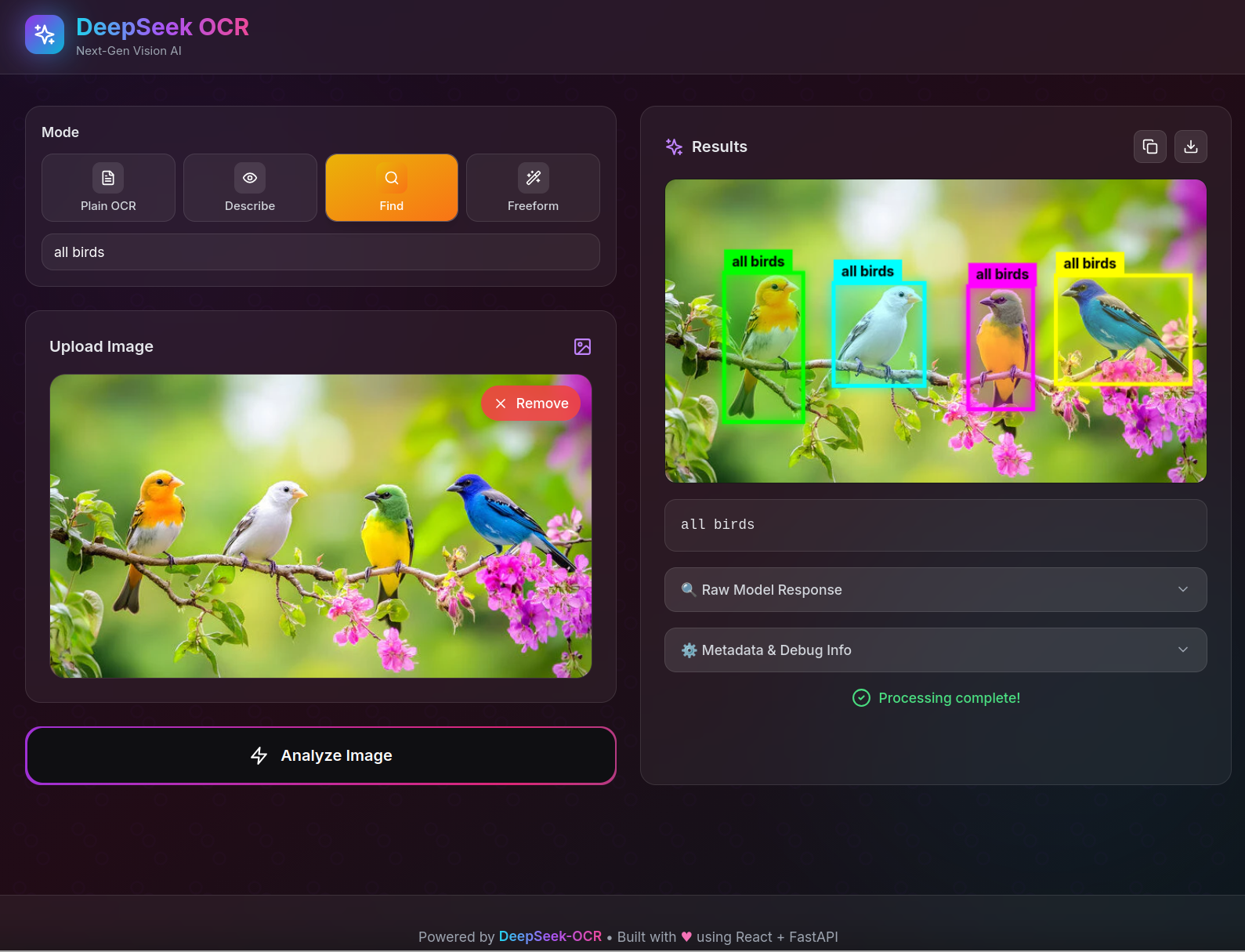
Here are some example images showcasing different OCR capabilities:
Visual Understanding
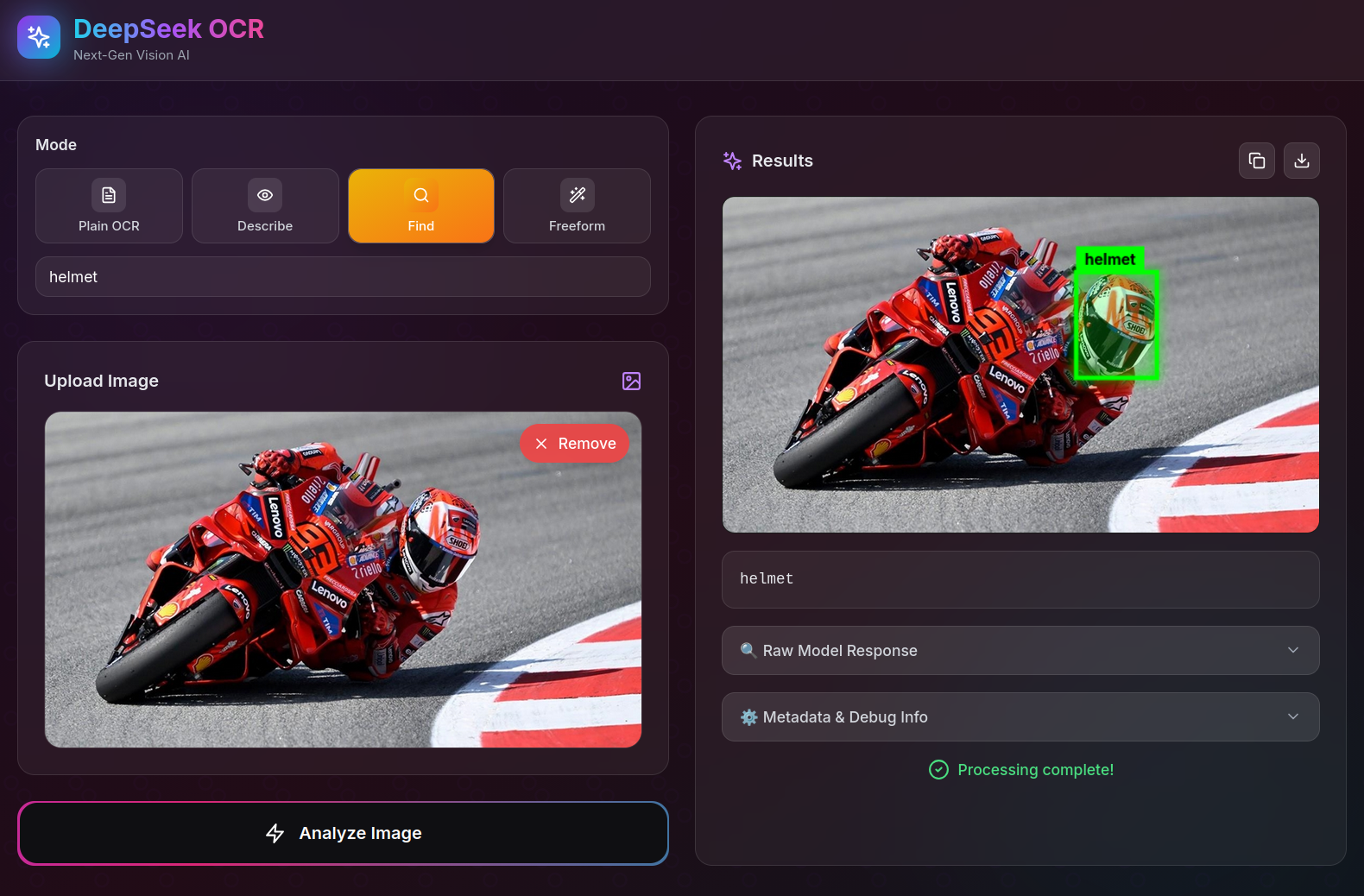
Table Extraction from Chart
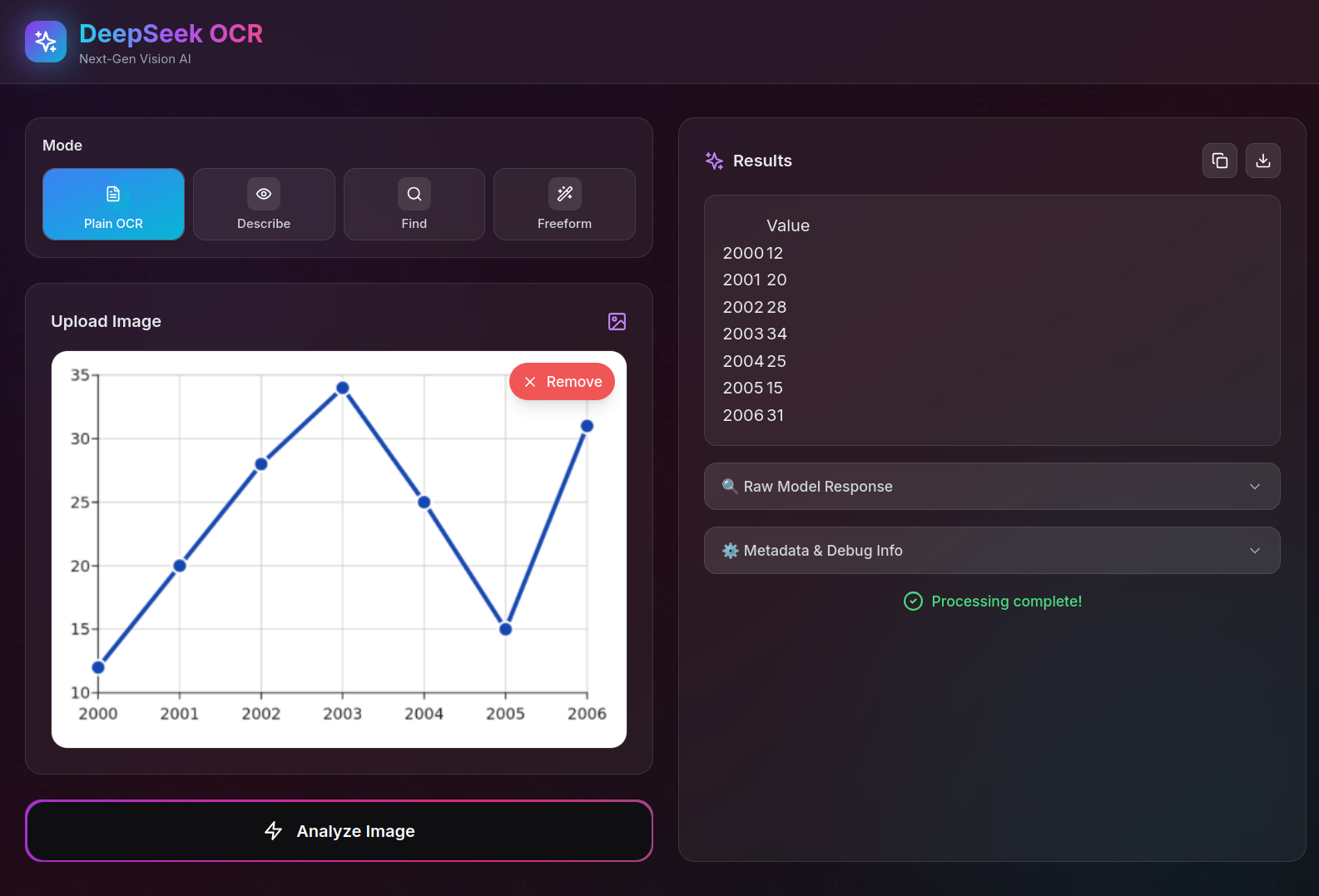
Image Description
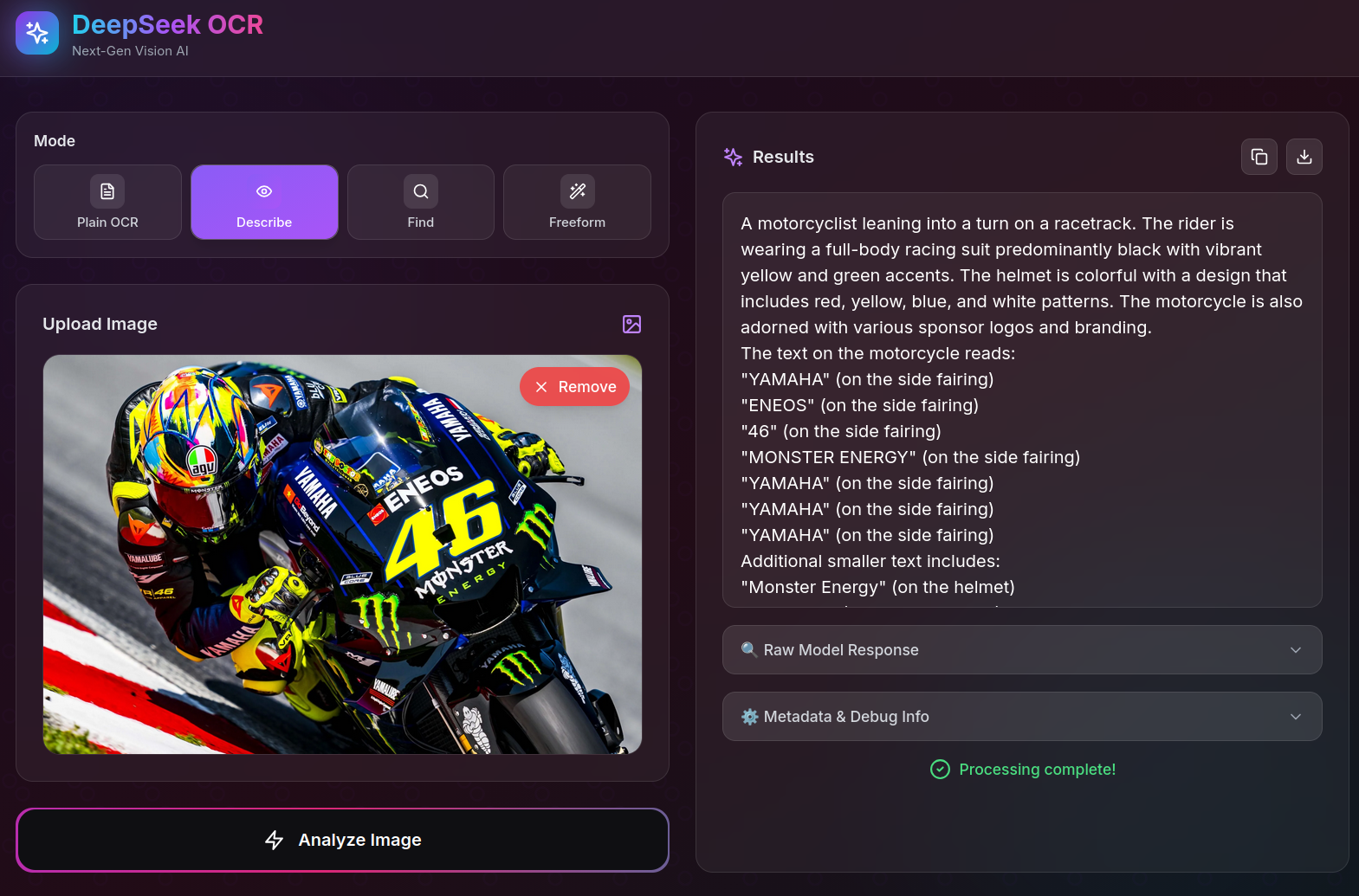
Troubleshooting
GPU not detected
nvidia-smi
docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
Port conflicts
sudo lsof -i :3000
sudo lsof -i :8000
Frontend build issues
cd frontend
rm -rf node_modules package-lock.json
docker-compose build frontend
License
This project uses the DeepSeek-OCR model. Refer to the model's license terms.
Note: Licensed under the MIT License. View the full license: LICENSE
Tags
Similar Tools
Lk Locator
Simple vibe coded Sri Lanka locator app
Panel Notes
Track electrical panel breakers
Fitdrop
Personal fashion exploration 1980-2025
GDevelop
Cross-platform game engine for game development
Demo2apk
Turn vibe coding ideas into Android apps
Indistocks
Desktop app for Indian stock exchange data